(Deutsche Version: siehe unten)
Dear CrossAsia users,
We are excited to share that our new service, the Newspaper Research Companion (NRC), is now available in early access!
Built by the CrossAsia Lab over the past year, the NRC is an AI-powered research platform that transforms how large digitized newspaper archives can be accessed and explored. It opens up historical press to intelligent, cross-lingual discovery for the first time and was supported by Der Beauftragte der Bundesregierung für Kultur und Medien.
What Is the Newspaper Research Companion?
The NRC enables researchers to query, read, and analyse historical newspaper collections across multiple languages through a single interface, working entirely in their own language. In its current version, the NRC covers over 32.9 million article chunks drawn from 66 newspaper titles in German, Chinese (Traditional, Simplified, and Classical), English, and Russian, spanning the years 1785 to 2014. To view the full list of included titles, see the Resources table on NRC homepage.
Rather than matching keywords, the NRC understands the intent behind a question and retrieves material that is genuinely relevant to the research need, much like asking a knowledgeable colleague who happens to have read millions of historical newspaper articles across multiple languages.
Why Early Access?
The NRC is the first iteration of a service we will be continuously improving, expanding the available materials and refining its design and features over time. Some of the underlying licensing agreements are still being finalised, which means the current collection does not yet reflect the full scope of what the NRC will eventually cover.
Key Features of the NRC
- Ask real research questions. Owing to our AI-powered semantic search, rather than entering isolated search terms, users can pose complex, interpretive questions. How did German and Chinese newspapers cover the same event? How did the framing of a political figure shift over decades? How did Russian, German, and Chinese press traditions diverge during the same international crisis? The NRC synthesizes answers drawn from across the corpus, grounded in the actual sources it retrieves. Users can browse all sources or filter by region, time period, source language, or specific publication. Questions can be posed in any language, including mixed-language queries, so key terms need not be translated. Users can set the language of the results, choosing between English, German, French, Korean, Japanese or Traditional Chinese, or the original language of each material.
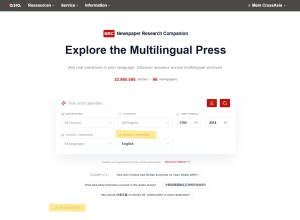
NRC search box with open filter feature including the result language setting and the resources table dropdown below.
- Access what was previously out of reach. A question posed in English can surface relevant articles from Russian, Chinese, or German-language sources, without the need for external translation support. The AI model captures meaning across languages rather than relying on surface-level word overlap.
- Understand sources at a glance. Every retrieved article is accompanied by an AI-generated summary in the user’s chosen language, making it possible to immediately assess the relevance and content of articles in Classical Chinese, Russian, or any other collection language, without having to read the original in full. Each result links directly to its original source, ensuring transparency and allowing CrossAsia users to verify the information and explore further with a single click.
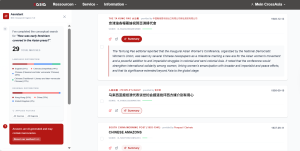
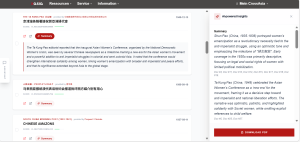
- Auto-generated synthesis. Beyond individual articles, the NRC generates a short research report drawing on retrieved sources, with full references to the underlying originals – suitable for annotation, integration into research workflows, or as a foundation for further enquiry. The report can be downloaded as a PDF.
How Does It Work?
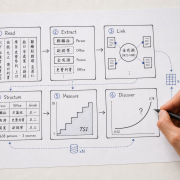
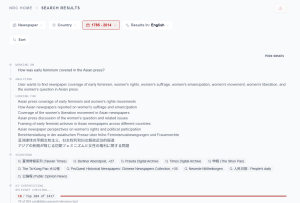
When a user poses a question, the NRC’s AI pipeline interprets the underlying information need, identifies historically significant terms across languages and time periods, and generates multilingual equivalents of key concepts to broaden coverage across the corpus. It then retrieves material across all supported languages simultaneously and filters results for relevance before generating a response grounded exclusively in the material that has passed the relevance check. Each step is transparently shown to the user as the system progresses:
All processing takes place within the IT infrastructure of the Staatsbibliothek zu Berlin. Licensed materials are never shown to unauthorized users. The NRC surfaces semantic context and links back to original sources without reproducing or replacing them. To learn more about our methodology, visit About Our Method on the NRC homepage.
Try It Now
We warmly invite you to explore the early access platform and share your impressions with us. Your feedback is invaluable for its continued development!
If you would like to take part in a 15-minute user interview and help shape the NRC’s future, please email x-asia@sbb.spk-berlin.de.
We hope you enjoy discovering the NRC!
Your CrossAsia Team
Liebe Nutzer:innen,
wir freuen uns, Ihnen mitteilen zu können, dass unser neuer Service, der Newspaper Research Companion (NRC), ab sofort im Early Access verfügbar ist!
Der im CrossAsia Lab entwickelte NRC ist eine KI-gestützte Rechercheplattform, die den Zugang zu großen digitalisierten Zeitungsarchiven grundlegend neu gestaltet. Erstmals wird die historische Presse einer intelligenten, sprachübergreifenden Recherche zugänglich. Das Projekt wurde unterstützt vom Beauftragten der Bundesregierung für Kultur und Medien.
Was ist der Newspaper Research Companion?
Der NRC ermöglicht es Forschenden, historische Zeitungsbestände in mehreren Sprachen über eine einzige Oberfläche abzufragen, zu lesen und zu analysieren – und das vollständig in der eigenen Sprache. In der aktuellen Version umfasst der NRC über 32,9 Millionen Artikelabschnitte aus 66 Zeitungstiteln in deutscher, chinesischer (traditionell, vereinfacht und klassisch), englischer und russischer Sprache aus den Jahren 1785 bis 2014. Die vollständige Liste der enthaltenen Titel finden Sie in der Quellentabelle auf der NRC-Startseite.
Anstatt bloß Schlagwörter abzugleichen, versteht der NRC die Intention hinter einer Frage und findet Material, das für das Forschungsanliegen tatsächlich relevant ist – ganz so, als würde man eine kundige Kollegin fragen, die zufällig Millionen historischer Zeitungsartikel in mehreren Sprachen gelesen hat.
Warum Early Access?
Der NRC ist die erste Ausbaustufe eines Services, den wir kontinuierlich weiterentwickeln werden, sowohl durch die Erweiterung der verfügbaren Materialien als auch durch die Verfeinerung von Design und Funktionen. Einige der zugrunde liegenden Lizenzvereinbarungen befinden sich noch in der finalen Abstimmung, sodass der aktuelle Bestand noch nicht den vollen Umfang dessen widerspiegelt, was der NRC künftig abdecken wird.
Die wichtigsten Funktionen des NRC
1. Stellen Sie echte Forschungsfragen. Dank unserer KI-gestützten semantischen Suche müssen Nutzer:innen keine isolierten Suchbegriffe mehr eingeben, sondern können komplexe, interpretative Fragen stellen: Wie berichteten deutsche und chinesische Zeitungen über dasselbe Ereignis? Wie veränderte sich die Darstellung einer politischen Persönlichkeit über Jahrzehnte hinweg? Wie unterschieden sich russische, deutsche und chinesische Pressetraditionen während derselben internationalen Krise? Der NRC erstellt synthetisierte Antworten aus dem gesamten Korpus, die auf den tatsächlich gefundenen Quellen beruhen. Nutzer:innen können alle Quellen durchsuchen oder nach Region, Zeitraum, Quellsprache oder einzelnen Publikationen filtern. Fragen können in jeder beliebigen Sprache gestellt werden, auch gemischtsprachig, sodass zentrale Begriffe nicht übersetzt werden müssen. Die Sprache der Ergebnisse lässt sich frei wählen: Englisch, Deutsch, Französisch, Koreanisch, Japanisch oder traditionelles Chinesisch – oder die Originalsprache des jeweiligen Materials.
NRC-Suchfeld mit geöffneten Filtern, darunter die Einstellung der Ergebnissprache, sowie darunterliegender ausklappbarer Quellentabelle.
2. Erschließen Sie bislang Unzugängliches. Eine auf Englisch gestellte Frage kann relevante Artikel aus russisch-, chinesisch- oder deutschsprachigen Quellen zutage fördern, ganz ohne externe Übersetzungshilfe. Das KI-Modell erfasst Bedeutung über Sprachgrenzen hinweg, anstatt sich auf oberflächliche Wortübereinstimmungen zu stützen.
3. Verstehen Sie Quellen auf einen Blick. Jeder gefundene Artikel wird von einer KI-generierten Zusammenfassung in der gewählten Sprache begleitet. So lässt sich die Relevanz und der Inhalt von Artikeln in klassischem Chinesisch, Russisch oder jeder anderen Sprache der Sammlung sofort einschätzen, ohne das Original vollständig lesen zu müssen. Jedes Ergebnis verlinkt direkt auf die Originalquelle. So können CrossAsia-Nutzer:innen die Informationen transparent nachvollziehen und mit einem einzigen Klick überprüfen oder vertiefend weiterrecherchieren.
4. Automatisch generierte Synthese. Über die einzelnen Artikel hinaus erstellt der NRC einen kurzen Forschungsbericht auf Grundlage der gefundenen Quellen mit vollständigen Verweisen auf die zugrunde liegenden Originale. Dieser eignet sich zur Annotation, zur Einbindung in Forschungsworkflows oder als Ausgangspunkt für weiterführende Untersuchungen. Der Bericht kann als PDF heruntergeladen werden.
Wie funktioniert das?
Wenn eine Frage gestellt wird, interpretiert die KI-Pipeline des NRC zunächst das zugrunde liegende Informationsbedürfnis, identifiziert historisch bedeutsame Begriffe über Sprachen und Epochen hinweg und generiert mehrsprachige Entsprechungen zentraler Konzepte, um die Abdeckung im Korpus zu erweitern. Anschließend ruft das System Material aus allen unterstützten Sprachen gleichzeitig ab und filtert die Ergebnisse nach Relevanz, bevor es eine Antwort generiert, die ausschließlich auf dem geprüften und als relevant eingestuften Quellenmaterial beruht. Jeder Schritt wird den Nutzer:innen während der Verarbeitung transparent angezeigt:
Die gesamte Verarbeitung findet innerhalb der IT-Infrastruktur der Staatsbibliothek zu Berlin statt. Lizenzierte Materialien verbleiben bei ihren jeweiligen Anbietern und werden nicht autorisierten Nutzer:innen zu keinem Zeitpunkt angezeigt. Der NRC stellt semantischen Kontext bereit und verlinkt auf die Originalquellen, ohne diese zu reproduzieren oder zu ersetzen. Mehr über unsere Methodik erfahren Sie unter „About Our Method“ auf der NRC-Startseite.
Jetzt ausprobieren
Wir laden Sie herzlich ein, die Early-Access-Plattform zu erkunden und uns Ihre Eindrücke mitzuteilen. Ihr Feedback ist für die Weiterentwicklung von unschätzbarem Wert!
Wenn Sie an einem 15-minütigen Nutzerinterview teilnehmen und die Zukunft des NRC mitgestalten möchten, schreiben Sie uns gerne an x-asia@sbb.spk-berlin.de.
Wir wünschen Ihnen viel Freude beim Entdecken des NRC!
Ihr CrossAsia-Team