Dieser Beitrag ist eine Verschriftlichung des gleichnamigen Vortrags über die ersten Erfahrungen, Daten aus dem ITR von CrossAsia in Gaia-X zu publizieren und auf diesem Wege der Forschung und vor allem den Digital Huminaties zur Verfügung zu stellen. Der Vortrag wurde am 11. Oktober 2023 im Rahmen der Europeana Tech Conference 2023 in Den Haag gehalten.
Ausgangspunkt der Reise Richtung Gaia-X stellt die CrossAsia Webseite dar. CrossAsia ist das von der Staatsbibliothek zu Berlin verantwortete Portal, in dem alle Services des von der DFG geförderten Fachinformationsdienstes Asien und weiteren Angebote gebündelt werden. Der Fachinformationsdienst richtet sich an Wissenschaftlerinnen und Wissenschaftler aus den asienbezogenen Geisteswissenschaften und hat seinen Schwerpunkt auf Ost-, Zentral- und Südostasien. Die Staatsbibliothek sammelt nicht nur Materialien aus und über diese asiatischen Regionen, sondern hat sich bereits vor mehr als 20 Jahren für eine e-preferred-Strategie entschieden. Wann immer ein elektronisches Medium wie Zeitschrift oder Buch dauerhaft lizenziert werden kann, wird kein gedrucktes Exemplar erworben, sondern das elektronische Dokument lizenziert. Hierbei versucht die Staatsbibliothek neben den überregionalen oder nationalen Zugangsrechten auch die Rechte für die lokale Archivierung der Dokumente inkl. Text- und Datamining-Rechten nach Verhandlungen zu erlangen. Neben den Einträgen in den Nachweissystemen kommt der Verwaltung der lizenzierten Daten wie Bilddaten, Volltexten, Film- und Tondokumenten eine besondere Bedeutung zu. Ein erster Dienst, der aus der Verwaltung der digitalen Objekte entwickelt wurde, ist die CrossAsia-Volltextsuche. Diese basiert neben eigenen digitalisierten und mit Volltexten ausgestatteten Objekten auf lizenzierten Objekten von Verlagen und anderen Anbietern. Hierbei handelt es sich hauptsächlich um Text- und Bildmaterialien aus historischen Quellen, von Büchern über wissenschaftliche Artikel bis hin zu aktuellen Zeitungen. Bislang sind insbesondere Materialien in Englisch und Chinesisch repräsentiert; das Angebot wird auch in Hinblick auf die anderen Sprachen kontinuierlich ausgebaut.
All diese Inhalte werden im sogenannten Integrierten Textrepository (ITR) archiviert. Technische Grundlage hier ist eine Infrastruktur basierend auf der Fedora Repository Software. Gleichzeitig stellen wir die Durchsuchbarkeit der Inhalte über einen Solr-Index dar. Dieser enthält momentan fast 70 Millionen Dokumente und ist weltweit eine einmalige Sammlung für lizenzfreie und lizenzbehaftete digitale Ressourcen in den Asienwissenschaften.
Aus diesem Grunde haben viele Wissenschaftlerinnen und Wissenschaftler ein großes Interesse, in diesen Inhalten Muster zu entdecken, neue Zusammenhänge zu erkennen und neue Erkenntnisse mit eigenen Algorithmen und Programmen durch Text- und Datamining zu gewinnen. Der FID Asien besitzt zwar das Recht, seine Nutzerinnen und Nutzern solche Analysen direkt durchführen zu lassen. Hierbei stellt sich jedoch die Frage, wie Code und Inhalte zusammenkommen?
Eine naheliegende Idee wäre ein zusätzlicher Service, der es Wissenschaftlerinnen und Wissenschaftlern ermöglicht, ganze Sammlungen aus dem ITR herunterzuladen. Allerdings ist die Datenmenge im ITR sehr groß, so dass unter Umständen mehrere Terrabyte von Daten heruntergeladen werden müssten. Dies kann je nach Netzwerkgeschwindigkeit Wochen dauern. Zudem wird die weitere Verbreitung der Daten mit dem Download unkontrollierbar, was für alle lizenzierten Inhalte äußerst kritisch ist und zu Vertragsverletzungen führen kann. Dies wiederum schafft Probleme mit Verlagen, mit denen die Staatsbibliothek Verträge geschlossen hat. Schließlich basiert ein Lizenzvertrag auf gegenseitigem Vertrauen, weshalb eine strengere Zugriffskontrolle auf die Daten notwendig ist.
Eine andere Idee ist, dass Wissenschaftlerinnen und Wissenschaftler in die Staatsbibliothek kommen und sich dort mit ihrem eigenen Laptop über die IT-Infrastruktur der SBB direkt mit dem ITR verbinden und dann die entsprechenden Analysen durchführen. Dies ist aus Zeit- und Kostengründen nicht immer realisierbar, vor allem wenn eine ferne Anreise notwendig ist. Und auch in diesem Fall muss kontrolliert werden, ob Daten in zu großem Umfang aus dem ITR abgezogen werden und die Staatsbibliothek damit die Kontrolle über ihre in den Lizenzverträgen eingegangenen Verpflichtungen verliert.
Ein weiteres Problem stellen die erforderlichen Computer-Ressourcen dar, die z.B. für das Training im Rahmen des maschinellen Lernens benötigt werden und die ein einfacher Laptop nicht bieten kann. Daher kann auch die Verfügbarkeit der notwendigen Rechenleistung ein Problem sein.
Ausgehend von dieser Problematik begann unsere Suche nach einer Möglichkeit, unsere Daten und unser ITR für Text- und Datamining zu öffnen. Dabei stießen wir auf Gaia-X. Gaia-X ist eine europäische Initiative für eine unabhängige Cloud-Infrastruktur, wobei es sich eher um ein Framework als um eine weitere Cloud-Plattform wie Amazon Webservices oder Google handelt, die sich in verschiedene Domänen aufgliedert.
Die wichtigsten Eigenschaften des Gaia-X Frameworks sind im Folgenden aufgeführt:
- Volle Souveränität über die eigenen Daten. Die Kontrolle über die Daten bleibt stets beim Eigentümer.
- Dezentralität, d.h., es gibt keinen zentralen Punkt im Netzwerk, der für das Funktionieren notwendig ist.
- Ein Regelwerk zur Schaffung von Vertrauen und spezielle Services (verfügbar als Open Source), die von allen Netzwerkteilnehmern genutzt werden können, um zu überprüfen, ob andere auch die Regeln einhalten. Gaia-X ist also ein föderales System mit implizitem Vertrauen.
- Gaia-X ist interoperabel, da es keine vorgeschriebene technische Infrastruktur für die Teilnahme gibt.
- Mit Gaia-X ist es möglich, fachspezifische Dataspaces zu erstellen und diese miteinander zu verknüpfen.
Abbildung 1 zeigt einen Überblick über die Gaia-X Domäne, die wir uns näher angeschaut haben. Links ist das Trust Framework mit den verbundenen föderierten Diensten dargestellt, die dazu genutzt werden können, um die Compliance von allen Teilnehmenden zu überprüfen. Rechts oben finden sich die Portale, die den Einstiegspunkt in die fachspezifischen Dataspaces in Gaia-X darstellen.
Alles, was in einem Portal veröffentlicht wird, wird im föderierten Katalog verzeichnet, der in der Abbildung neben den Portalen zu sehen ist. Dieser Katalog ist unabhängig von den Portalen und enthält Informationen über alle Assets in Gaia-X. Nutzerinnen und Nutzer besuchen ein Portal und sehen die Inhalte abhängig vom Portal in einer fachspezifischen Ansicht des föderierten Katalogs. Die Inhalte sind jedoch nicht an das Portal gebunden und können jederzeit und überall im Gaia-X-Netzwerk genutzt werden. Auch deswegen ist Gaia-X als dezentral zu bezeichnen.
Um herauszufinden, wie uns diese Eigenschaften unterstützen können, um Text- und Datamining im ITR zu ermöglichen, haben wir ein Proof-of-Concept gestartet. Das Ergebnis war ein eigenes CrossAsia Portal in Gaia-X. Inhalte eines solchen Portals sind sogenannte Service-Offerings in Gaia-X. Dies kann entweder ein Dataset oder ein Algorithmus sein. Für ein Dataset besteht die Möglichkeit des gesicherten Downloads, was bedeutet, dass die URL des Datensatzes niemals sichtbar wird. Gleichzeitig kann zum Beispiel die gesamte Anzahl an Downloads festgelegt werden.
Eine weitere Möglichkeit besteht darin, Compute-To-Data für ein Dataset zu aktivieren. Dies ermöglicht es Nutzerinnen und Nutzern, die Daten mit einem veröffentlichten Algorithmus zu verknüpfen und einen Compute Job zu starten. Die Nutzerinnen und Nutzer erhalten nur die Ergebnisse ihres Compute-Jobs, nicht die Daten selbst. Auf diese Weise können wir die Daten aus unserem ITR für Text- und Datamining anbieten, ohne dass jemand Daten herunterladen oder verschieben muss.
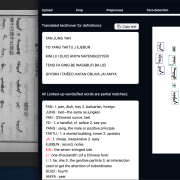
Dies funktioniert, weil hier das Ocean Protocol die technische Grundlage von Gaia-X darstellt. Abbildung 2 zeigt einen vereinfachten technischen Ablauf für Compute-To-Data. Die Schritte sind relativ einfach: zunächst suchen die Nutzerinnen und Nutzer die Daten und den Algorithmus aus dem föderierten Katalog (vorausgesetzt, es bestehen entsprechende Zugriffsrechte). Dann werden Daten und Algorithmus in einen isolierten Execution Pod geladen, der innerhalb einer Kubernetes-Umgebung startet. Einzig die Ergebnisse des Algorithmus und Logfiles zur Ausführung werden dann dem Nutzer oder der Nutzerin zur Verfügung gestellt. Am Ende wird der Execution Pod gelöscht.
Copyright 2023 Ocean Protocol Foundation
Das Veröffentlichen von Datasets und Algorithmen und deren Verbindung hat wie in der Theorie beschrieben funktioniert. Daher kann der Proof-of-Concept als Erfolg angesehen werden: eine Bibliothek kann Datasets in Gaia-X veröffentlichen, Wissenschaftlerinnen und Wissenschaftler können einen Algorithmus veröffentlichen und beides über das Portal kombinieren. Die gewünschten Ergebnisse werden zur Verfügung gestellt, ohne das die Sicherheit der Daten gefährdet wird – keine Downloads sind notwendig und alle Daten bleiben bei der Institution, die sie veröffentlicht hat.
Mit der Ersteinrichtung des Portals muss jedoch festgestellt werden, dass noch einige Verbesserungen notwendig sind, bevor die Lösung in größerem Umfang gut genutzt werden kann. Wer das Portal ausprobieren möchte, wird feststellen, dass der Einstieg in das Gaia-X Netzwerk nicht einfach ist und einiger Erklärungen bedarf. Da es sich bei der Datenbank des föderierten Katalogs um einen Distributed Ledger handelt, wird ein Wallet zur Identifizierung und Rechtegewährung benötigt. Daher muss im Browser ein Wallet (z.B. MetaMask) installiert und konfiguriert werden. Nach dem Einstieg ins Netzwerk ist jedoch die Veröffentlichung von Datasets und Algorithmen recht einfach, wenn auch die Verwendung von Daten bzw. das Starten eines Compute-Jobs eine Reihe von Bestätigungen bestimmter Transaktionen auf dem Ledger erfordert.
Zusammenfassend lässt sich feststellen, dass Gaia-X eine interessante neue Möglichkeit für GLAM-Institutionen ist, ihre schützenswürdigen Daten anzubieten. Gaia-X ist derzeit noch stark von wirtschaftlichen und industriellen Interessen mit einer starken kommerziellen Ausrichtung getrieben. Dennoch haben wir uns entschieden, vor allem aufgrund der guten Ergebnisse, unsere Aktivitäten in Gaia-X fortzuführen und den Proof-of-Concept zu einer Pilotanwendung weiterzuentwickeln. Hier arbeiten wir an ersten Verbesserungen der User-Experience und werden in Kürze weitere Use-Cases mit wissenschaftlichem Fokus durchführen. Wir engagieren uns gleichzeitig in der Gaia-X und Ocean-Protocol-Community, um auch nicht-kommerzielle Anwendungsfälle in Gaia-X besser zu ermöglichen und Gaia-X zu einem wissenschaftlichen Ökosystem für fachspezifische Dataspaces weiterzuentwickeln.
Basierend auf unseren Erfahrungen aus dem Proof-of-Concept möchten wir Einrichtungen des Kulturerbes vorschlagen, darüber nachzudenken, wie Gaia-X und das Ocean Protocol sie dabei unterstützen können ein Fullstack-Dataprovider zu werden. Und eben nicht nur ein Dataprovider für Metadaten, um Kulturartefakte zu finden, nicht nur ein Dataprovider für Texte zum Lesen, Audios zum Hören, Bilder oder Videos zum Ansehen oder Forschungsdaten zum Analysieren. Sondern vielmehr ein Dataprovider, der solche Kulturdaten in hoher Qualität auch für Algorithmen und Netzwerke für maschinelles Lernen anbietet und dabei – sofern notwendig – die Hoheit über die Daten behält.
Derzeit werden Large Language Models stark von großen Unternehmen wie OpenAI, Google oder Facebook kontrolliert. Wenn jedoch jeder die Möglichkeit erhält, seine eigenen Modelle mit Daten von GLAM- Institutionen zu trainieren, kann das maschinelle Lernen demokratisiert werden. Da jeder Zugang zu den Daten hat, die er oder sie für seine Algorithmen benötigt – entweder zu freien Daten oder bei lizenzierten Daten dort, wo ein entsprechendes Zugriffs- und Lizenzrecht besteht. Neue Ansätze wie Federated Learning können dabei helfen und den Prozess sogar noch stark vereinfachen. Unser Ziel ist es, das Training künstlicher Intelligenz zu verbessern, indem wir unsere digitalen Lesesäle für die Algorithmen öffnen und nicht nur die neuen Möglichkeiten der künstlichen Intelligenz selbst zu nutzen.
Referenzen
Wenn Sie interessiert sind, die Lösung zu testen und Unterstützung benötigen, wenden Sie sich bitte an x-asia(at)sbb.spk-berlin.de

 SBB-PK
SBB-PK