Gastbeitrag von Dr. Thies Staack (Centre for the Study of Manuscript Cultures, University of Hamburg)
(Die deutschsprachige Version finden Sie im Stabi-Blog)
During the past few years, I have been conducting a research project on the collecting and exchange of medical recipes in 19th and early 20th century China at the Centre for the Study of Manuscript Cultures (CSMC) in Hamburg. Since manuscripts, both bound recipe books and individual recipes on loose leaves, played an important role in this respect, the Unschuld collection of Chinese medical manuscripts is an invaluable source for my research.
Among the close to 1,000 manuscripts from the Unschuld collection now housed at the Staatsbibliothek zu Berlin Preußischer Kulturbesitz (SBB-PK), there is a small thread-bound volume with an inconspicuous outside appearance but an extraordinarily rich content of overall roughly 800 mostly medical recipes. The manuscript with the shelf mark “Slg. Unschuld 8051” was produced in 19th century Canton and attests to a vibrant exchange of medical recipes during that period. I have introduced it in some more detail elsewhere. According to the description in the catalogue of the collection, published by Paul U. Unschuld and Zheng Jinsheng in 2012, the manuscript does not have an original title, which would usually be found on the front cover or on the first page of a volume. The title provided in the catalogue – Yifang jichao 醫方集抄 or “Hand-copied collection of medical formulas” – was obviously assigned by Unschuld and Zheng based on its content.

Fig. 1: Slg. Unschuld 8051, opened at the table of contents (photo by the author).
The fact that Slg. Unschuld 8051, like many other manuscripts from the Unschuld collection, has already been digitised is of tremendous help for my research. Still, to be able to thoroughly assess the materiality of this written artefact, for example, to get a feel for its size and weight, I went to Berlin to inspect Slg. Unschuld 8051 in the SBB reading room in April 2022. The first surprise was just how small and portable the volume is (see Fig. 1). It would easily fit into a pocket or sleeve and the stains on its covers suggest that it may indeed have been carried around a lot by its previous owners.

Fig. 2: The bottom edge of Slg. Unschuld 8051 under normal interior light (photo by the author).
When I turned the manuscript in my hands, I noticed what appeared to be writing with ink on the bottom of the volume (see Fig. 2). For some of the thread-bound Unschuld manuscripts images of the top, front and bottom edge as well as the spine have been included in the digitised version. This is, unfortunately, not the case for Slg. Unschuld 8051, which was digitised already in 2014. Hence, this was the first time I got to see the bottom edge of the manuscript. Due to the darkening of the paper at the edges, it was difficult to decipher any writing, but fortunately I had brought a portable digital microscope (Dino-Lite) from Hamburg, which allows analysis with the help of light in the invisible spectrum (ultraviolet and infrared light).
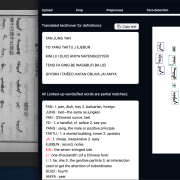
Carbon ink, which was traditionally used in China, is much more clearly visible under infrared light than it is under daylight. The infrared images taken with the Dino-Lite showed clearly discernible brushstrokes (see Fig. 3). Since the area that can be photographed with the microscope’s magnification is rather small, I had to piece together several images to be able to decipher whole characters (see Fig. 4), but this was sufficient to ascertain the presence of writing.

Fig. 3: One of the infrared images taken with the help of the Dino-Lite microscope (photo by the author).

Fig. 4: Combination of four Dino-Lite infrared images, together showing the character 世, with the help of image processing software (processed image by the author).

Fig. 5: Setup of the Opus Apollo infrared reflectography (IRR) camera above Slg. Unschuld 8051 in the Berlin State Library storage (photo by the author).
In order to acquire a high-quality infrared image of the whole bottom edge, my colleagues Ivan Shevchuk, Kyle Ann Huskin and Dr. Olivier Bonnerot from the CSMC helped me capture images with a professional infrared reflectography (IRR) camera (Opus Apollo) in September 2022 (see Fig. 5). Finally, it was possible to decipher the entire inscription of five characters (see Fig. 6).
The four larger characters, which must be read choushi zhencang 酧世珍藏, from right to left, on first sight resemble a typical ownership mark of a book collector. The expression zhencang 珍藏 “treasured collection (of)” together with a personal name could constitute a statement of ownership. However, book collectors more commonly used a seal stamp and red ink to apply their ownership mark. The fifth character in slightly smaller script to the very right (shang 上) hints towards the possibility that what we have here might rather be the title of the present recipe collection. Since the table of contents at the beginning of Slg. Unschuld 8051 lists recipes in a “first volume” (shang juan 上卷) and a “second volume” (xia juan 下卷), it is clear that the recipe collection comprised overall two volumes. Comparison with the actual recipe entries shows that the present volume is indeed the first of the two, which accords well with the small character written on the bottom edge. It is also worth pointing out that traditional thread-bound books – whether handwritten or printed – often had their title inscribed on their bottom edge in addition to the cover or title page. The reason for this is a common way of storage, with books being shelved lying flat on their back with the bottom edge facing towards the front. Hence, a title placed at this position is legible while the book is stored on a shelf, similar to the title on the spine of a “Western” book.

Fig. 6: Calibrated infrared reflectography (IRR) image of the bottom edge of Slg. Unschuld 8051 (photo by Olivier Bonnerot, Kyle Ann Huskin and Ivan Shevchuk).
If choushi zhencang 酧世珍藏 is in fact the title of this recipe book, it was probably selected by the compiler of the recipes for his personal collection. At least, this title is not found in the union catalogue of Chinese medical writings. The first two characters – with 酧 being a common variant of 酬 – seem to echo the title of the popular 19th c. household encyclopaedia Choushi jinnang 酬世錦囊 “Brocade Bag of Exchange with the World”, which provided guidance on etiquette and proper social interaction. As part of the title of a recipe collection, the expression “exchange with the world” could rather refer to the way in which the compiler got hold of the recipes, many of which are indeed noted as having been received from relatives, friends or acquaintances in Canton. Hence, it might be understood as “Treasured Collection of (Recipes obtained through) Exchange with the World”.
This example showcases not only the advantages of infrared reflectography, which can allow to decipher otherwise illegible writing on manuscripts. It also points to the fact that inclusion of images of all sides of a manuscript in its digital version – in the case of thread-bound volumes also the edges and the spine – would greatly benefit research. Nevertheless, it must be stressed that even this can never entirely replace a first-hand inspection of the original written artefact in the reading room.
The data set with infrared reflectography images of Slg. Unschuld 8051 has been published as:
Olivier Bonnerot, Kyle Ann Huskin, Ivan Shevchuk and Thies Staack (2025), Infrared Reflectography Images of the Writing on the Bottom Edge of Slg. Unschuld 8051, http://doi.org/10.25592/uhhfdm.16994.
Acknowledgements:
The author thanks Dr. Cordula Gumbrecht and Dr. Andreas Janke for valuable suggestions on an earlier draft of the text.
The research behind this contribution was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC 2176 “Understanding Written Artefacts: Material, Interaction and Transmission in Manuscript Cultures”, project no. 390893796. The research was conducted within the scope of the Centre for the Study of Manuscript Cultures (CSMC) at the University of Hamburg.
Feature image:
Two pages from the table of contents of Slg. Unschuld 8051, showing the recipes at the end of the first and the beginning of the second volume. Staatsbibliothek zu Berlin – PK, Slg. Unschuld 8051, f. 23v-24r, scan pages [48]-[49] (Retrieved from http://resolver.staatsbibliothek-berlin.de/SBB0000603200000048 and http://resolver.staatsbibliothek-berlin.de/SBB0000603200000049)


 SBB-PK
SBB-PK