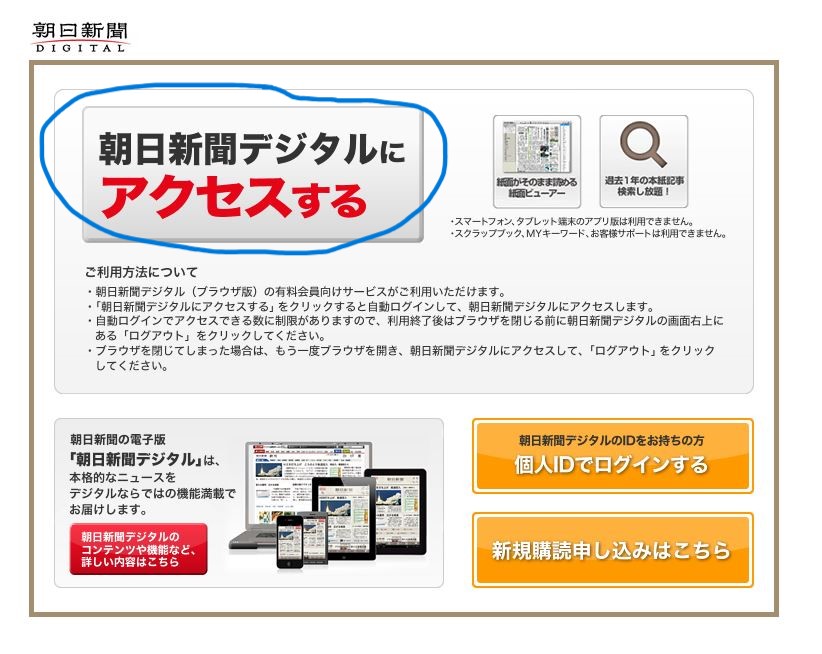
Alles neu bei der Asahi Shimbun | Everything new concerning the Asahi Shimbun
Als neue Lizenz steht ab sofort für registrierte Nutzer:innen die japanischen Zeitung Asahi Shimbun Digital zur Verfügung. Loggen Sie sich wie üblich ein und rufen Sie das Angebot über die Datenbankseite von CrossAsia auf. Anschließend klicken Sie auf dem nächsten Bildschirm unbedingt auf「朝日新聞デジタルにアクセスする」und gelangen somit zu den Beiträgen. Nach der Recherche ist es zwingend notwendig, die Webseite rechts oben über「マイページ」und den im dortigen Pull Down Menü angebotenen Logout-Button wieder zu verlassen, da sonst unnötig Simultanzugriffe blockiert werden. Ein einfaches Schließen des Browsers beendet NICHT die Session beim Anbieter. Vielen Dank für die Kooperation!
Laut Aussage des Anbieters waren die Artikel der Papier- und der digitalen Ausgabe ursprünglich identisch. Inzwischen werden jedoch vermehrt eigenständige Artikel in der digitalen Ausgabe veröffentlicht, von denen nur 10-100 monatlich in die Datenbank Asahi Shimbun Cross-Search aufgenommen werden. Insofern sind die Inhalte der Asahi Shimbun Digital und der bereits seit längerem für CrossAsia lizenzierten Datenbank Asahi Shimbun Cross-Search nicht völlig übereinstimmend. Die Inhalte der Asahi Shimbun Digital sind jedoch nur vorübergehend verfügbar: Zeitungsartikel für 12 Monate (danach weiterhin in der Asahi Shimbun Cross-Search erhältlich), originale Online Artikel für fünf Jahre, Scans der Zeitungsseiten: 90 Tage, wohingegen die Artikel der Datenbank Asahi Shimbun Cross-Search dauerhaft archiviert werden.
Wir bedanken uns herzlich bei allen Nutzenden, die uns eine Rückmeldung gegeben haben! Ihr Feedback ist für uns wichtig und wertvoll! Vielen Dank für Ihr Engagement!
Darüber hinaus sind für die Asahi Shimbun Cross-Search weitere Inhalte lizenziert worden:
〇朝日新聞クロスサーチ「基本」
・朝日新聞1985~、AERA、週刊朝日
・朝日新聞縮刷版1945~1999(昭和戦後、平成)
・現代用語事典「知恵蔵」
・朝日新聞縮刷版1879~1945(明治・大正、昭和戦前)
・人物データベース
・歴史写真アーカイブ
・アサヒグラフ
・英文ニュースデータベース
〇Neu: 全国の地域面 地域面検索β版 >> die Jahrgänge 1991-1996 sind via Volltextsuche recherchierbar; alle anderen Jahrgänge nur via Datum (Erweiterung der Volltextsuche ist in Arbeit)
〇Neu: 戦前の外地版
___
The Japanese newspaper Asahi Shimbun Digital is now available as a new license for registered users. Log in as usual and access this resource via the CrossAsia database page. Then click on「朝日新聞デジタルにアクセスする」on the next screen to access the articles. After searching, it is absolutely necessary to leave the website via「マイページ」and use the logout button offered in the pull-down menu at the top right, as otherwise simultaneous accesses will be blocked unnecessarily. Simply closing the browser does NOT end the session with the provider. Thank you for your co-operation!
According to the provider, the articles in the paper and digital editions were originally identical. In the meantime, however, more and more independent articles are being published in the digital edition, of which only 10-100 are included in the Asahi Shimbun Cross-Search database each month. In this regard, the contents of the Asahi Shimbun Digital and the Asahi Shimbun Cross-Search database already licensed for CrossAsia are not completely identical. However, the contents of the Asahi Shimbun Digital are only available temporarily: newspaper articles for 12 months (afterwards still available in the Asahi Shimbun Cross-Search), original online articles for five years, images of the newspaper pages: 90 days, whereas the articles in the Asahi Shimbun Cross-Search database are permanently archived.
We would like to thank all users who commented on this resource! Your feedback is important and valuable to us! Thank you for your commitment!
In addition, additional content has been licensed for the Asahi Shimbun Cross-Search:
〇朝日新聞クロスサーチ「基本」
・朝日新聞1985~、AERA、週刊朝日
・朝日新聞縮刷版1945~1999(昭和戦後、平成)
・現代用語事典「知恵蔵」
・朝日新聞縮刷版1879~1945(明治・大正、昭和戦前)
・人物データベース
・歴史写真アーカイブ
・アサヒグラフ
・英文ニュースデータベース
〇New: 全国の地域面 地域面検索β版 >> the years 1991-1996 can be searched via full-text search; all other years only via date (extention of the full-text search is in progress)
〇New: 戦前の外地版