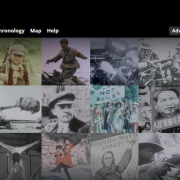
Neues Themenportal in CrossAsia
Gerade haben wir ein neues Themenportal auf unseren CrossAsia Seiten online gestellt. Es gibt einen Überblick über die Manjurica-Sammlung der Staatsbibliothek zu Berlin. Diese zählt mit rund 550 Titeln zu den großen Sammlungen von Literatur in dieser Sprache in der Welt. Ihre Geschichte reicht zurück bis in die frühen Anfänge der Bibliothek in der Mitte des 17. Jahrhunderts, da der Große Kurfürst Friedrich Wilhelm von Brandenburg (1620-1688) seine Privatbibliothek für Wissenschaftler und interessierte Gäste öffnete. Möglicherweise war es Andreas Müller (1630-1694), der erste Kurator der chinesischen Sammlung in jener Zeit, der die ersten manjurischen Titel für die Bibliothek erwarb. Die Sammlung wuchs im Laufe der Jahrhunderte mit unterschiedlicher Intensität, aber stets kontinuierlich. Renommierte Spezialisten für die Sprache, Geschichte und Kultur der Manju trugen bis in die jüngste Vergangenheit zum Heranwachsen einer wertvollen Sammlung an Manjurica bei. Im aktuell veröffentlichten Themenportal wird ihre Geschichte und ihr Wachsen sowie die Sichtbarmachung derselben in den Digitalen Sammlungen der Staatsbibliothek beschrieben, es werden Hinweise zum Auffinden der Manjurica in letzteren bzw. in unseren Katalogen gegeben. Weitere Themenportale zu unseren Sammlungen bzw. Projekten finden Sie hier.



 Zugangsdaten ermitteln: Sollten Sie Ihre Zugangsdaten einmal nicht parat haben, können Sie diese ab sofort online ermitteln. Für den Benutzernamen benötigen Sie Ihre im System hinterlegte E-Mail Adresse, für das Passwort den Benutzernamen. Sie finden den
Zugangsdaten ermitteln: Sollten Sie Ihre Zugangsdaten einmal nicht parat haben, können Sie diese ab sofort online ermitteln. Für den Benutzernamen benötigen Sie Ihre im System hinterlegte E-Mail Adresse, für das Passwort den Benutzernamen. Sie finden den 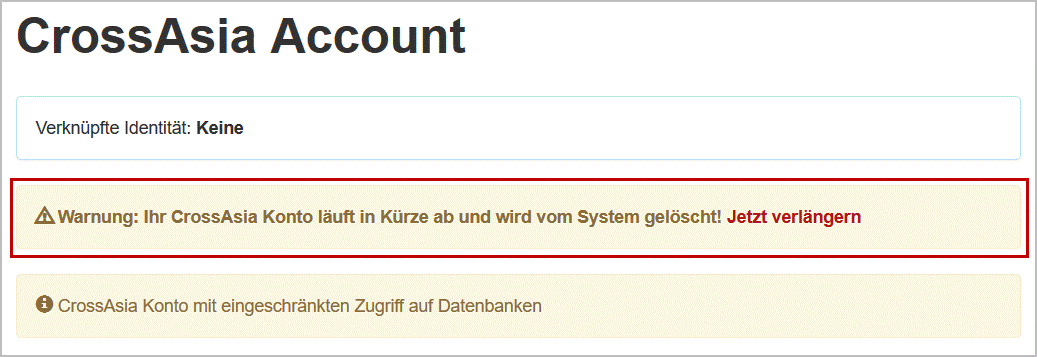




 Durch die Zusammenarbeit von
Durch die Zusammenarbeit von