The 23rd Conference of the European Association for Chinese Studies (EACS) took place August 24 – 27, 2021. It was hosted as an online conference by the East Asian Institute at Leipzig University.
During the preparation of and while accompanying the conference, CrossAsia had called for your participation in investigating the research conditions in China-related sciences in Europe.
We would like to take this opportunity to sincerely thank you for your participation in the survey, the aim of which was to better understand the needs and wishes within the research community and to learn more about the conditions and requirements in the China-related sciences in Europe.
Together with European partner libraries, we would like to contribute to sustainably improving the conditions for Asia-related research in Europe by building a European knowledge- and licensing-network. Therefore, we wanted to find answers to questions regarding the prioritisation of different types of resources, the understanding of the process of licensing e-media, the spread and utilisation of methods in Digital Humanities (DH), as well as the international networking of scholars and the resulting synergies when accessing resources.
These answers will be given below.
Characterisation of the Participants
A total of 630 persons participated in the 23rd EACS. We received 132 complete and correctly filled-in questionnaires. Of these, only questionnaires from people who are presently associated with a European research institution were evaluated.
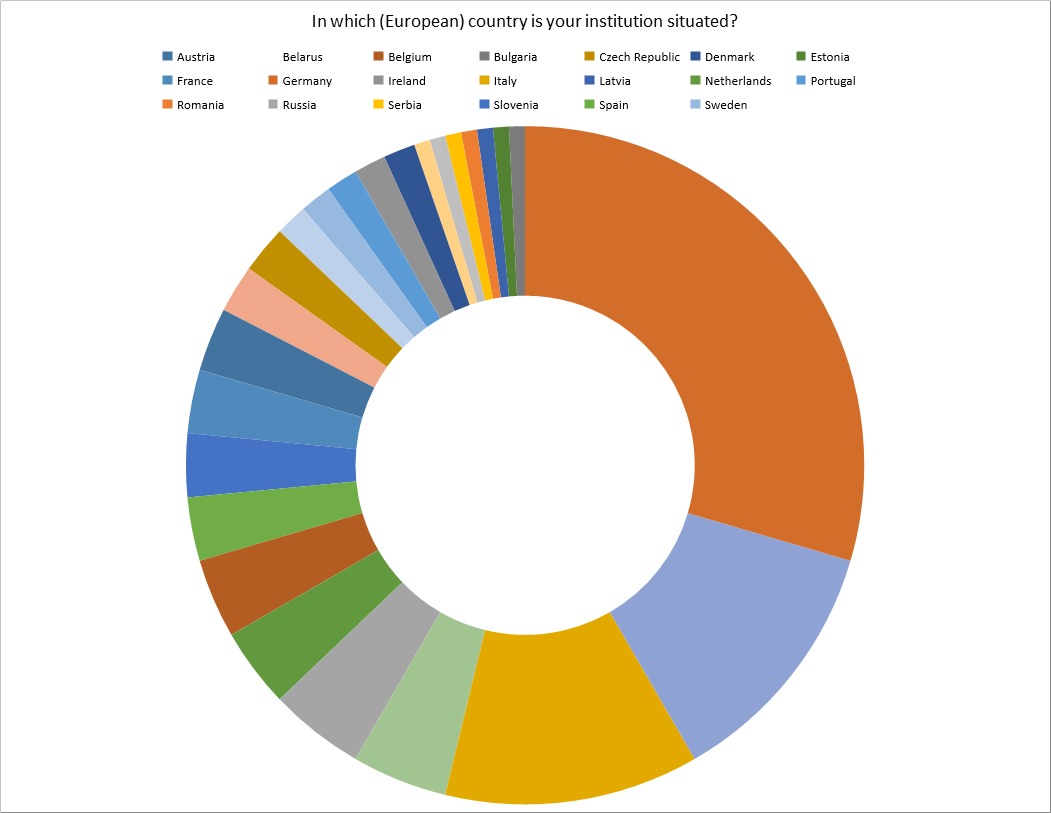
Scholars from 24 European countries took part in the survey, the majority of which are working in Germany (29%), followed by United Kingdom and Italy (12, % each). The remaining countries score under 5% each.
In Germany, the Fachinformationsdienst Asien (FID Asien, i.e., Special Subject Information Service Asia) and the online-platform CrossAsia provide a well-groomed range of materials to supply researchers with resources on Asia-sciences, especially, the China-related ones.
It is against this background, and in view of the comparatively high number of people working in Germany who participated in the survey, that a certain imbalance in the answers will very likely be introduced into the considerations following below.
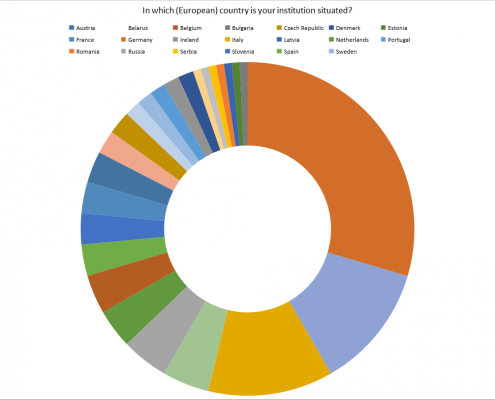
Ill. 1. Survey participants according to country.
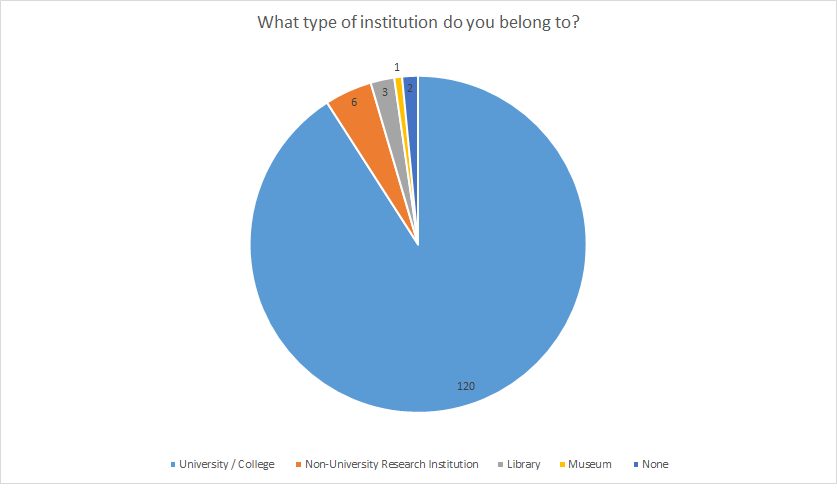
The clear majority of participants (98%) is active at an academic institution. The majority (90%) of these, again, at a university or college. Generally, these places do grant access to a library in order to provide the required resources.
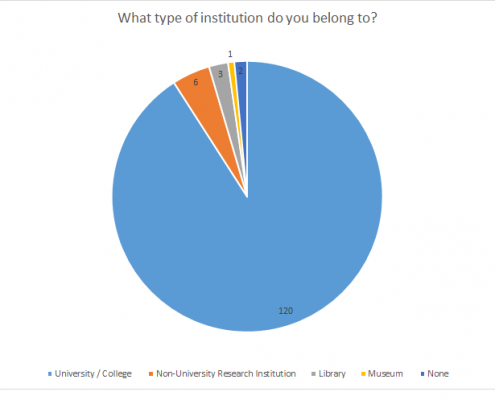
Ill. 2. Institutional affiliation of the persons interviewed.
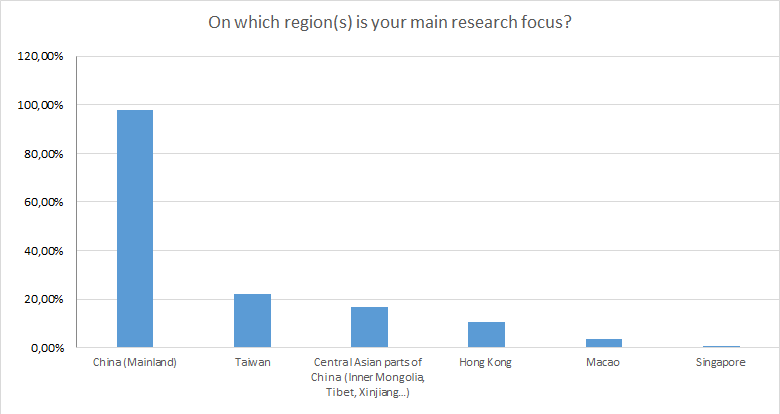
Unsurprisingly, more than 97% of the interviewed identified Mainland China as the core of their research interests; beyond that, over 21% named Taiwan. As a rule, littoral states of China are not taken into consideration in research. Individual researchers, however, are working on topics that also relate to Japan, South Korea, Mongolia, Russia, South East Asia and, to a lesser degree, South Asia.
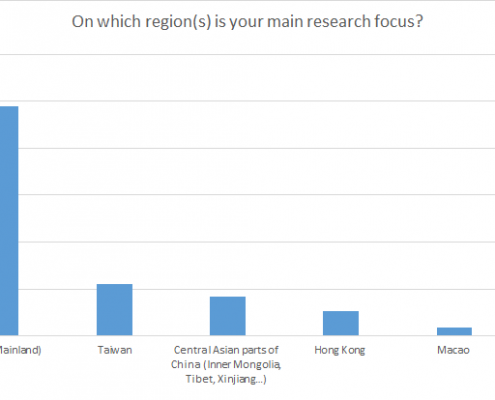
Ill. 3. Visual display of the main research regions (up to three entries per person allowed).
Regarding the thematic orientation of the research contents, it is obvious that classical, text-oriented, themes were the strongest group (36%) of answers of the interviewed persons from all European states participating. The feedback from Russia was an exception. Here, all participants indicated that history was not among their main interests.
Another strong research area is literature/philology (25%). Smaller areas of research are history of art, linguistics, philosophy, political science, religious science and, sociology (ca. 10% each).
Only a few researchers (>5%) study anthropology, archaeology/pre- and early history, economics, education/educational sciences, human geography, law, library and information sciences, and media/information/communication sciences. The evaluation results show that the “traditional” fields of China-related sciences are still a the majority. But smaller, or newer, scholarly fields are also present. The heterogeneity of European China-related research mirrors the answers of the participants in the survey.
Access to Resources
The survey intended to provide an overview of the access options to information resources in European China-related research.
Central in this context is the question of the meaning, the relevance, of different types of sources. The survey differentiates between print- and online-resources. Here, all resources are labelled e-resources only when they exist as sources and special subject information available online, in all different kinds, e.g., e-books, digital journals, licensed databases, or Open Access materials.
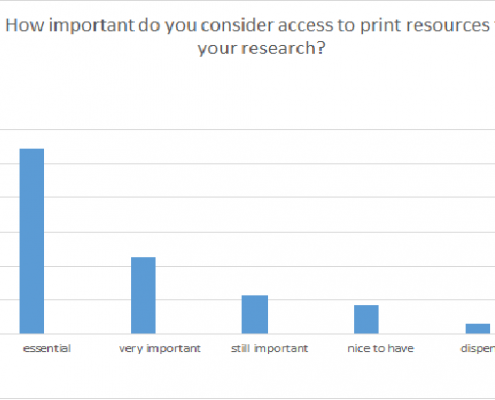
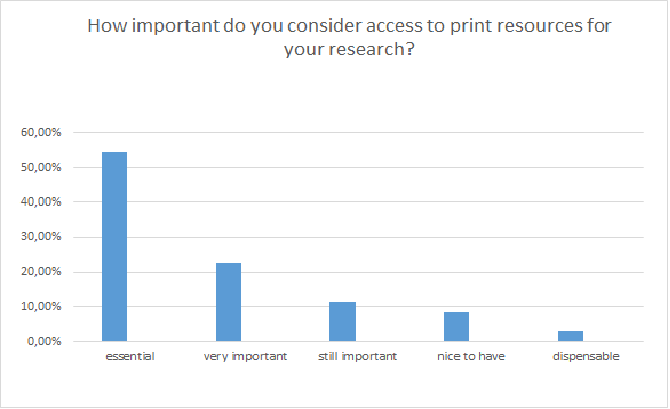
Ill. 4. Importance of print resources for participants.
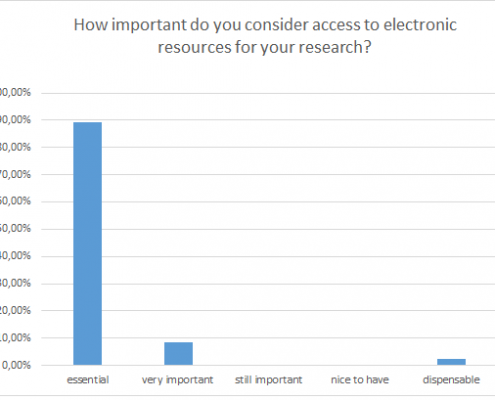
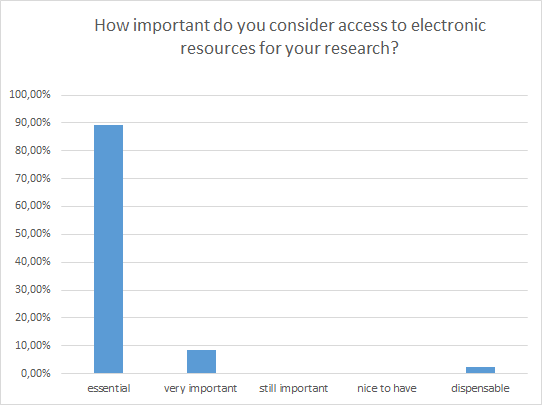
Ill. 5. Importance of e-resources for participants.
The majority of participants in this survey (89%) rated e-resources as more important than printed materials. This shows that access to electronic resources has become essential for successful research. Looking at the German participants only, this impression gets marginally stronger (ca. 95% of the German participants consider e-resources essential). Nevertheless, printed media also maintain a strong position: 87% of the participants consider them essential or, still essential, respectively.
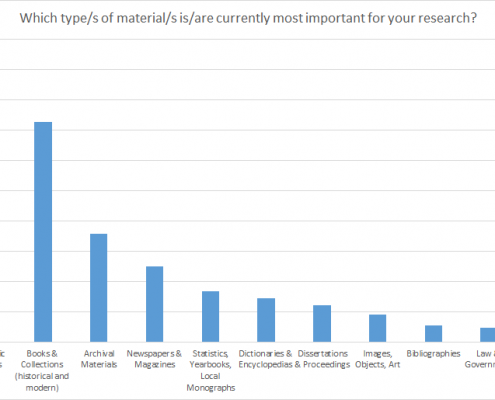
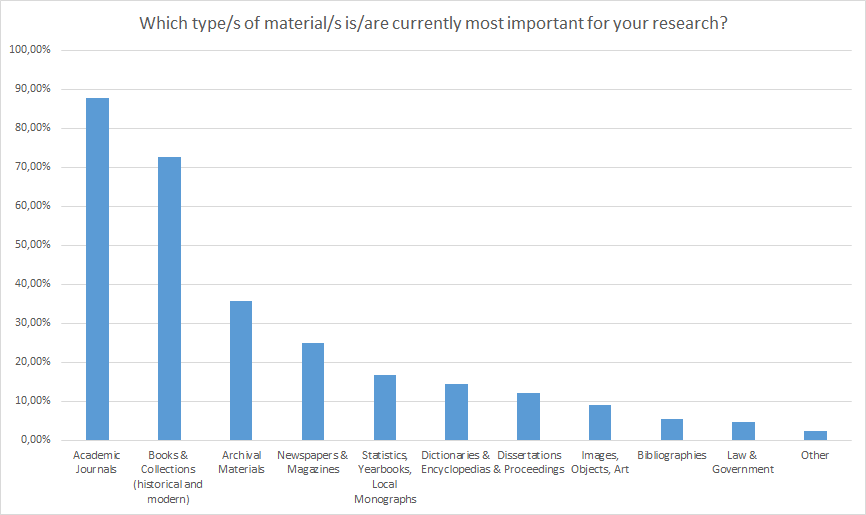
Ill. 6. Usage of different types of material (up to three entries per person allowed).
These types of material reflect the interviewees’ research interests which are predominantly historical or, philological/linguistical.
Access to E-Resources
Besides the confirmed need for e-resources, their availability and accessibility are of central concern for China-related research in Europe.
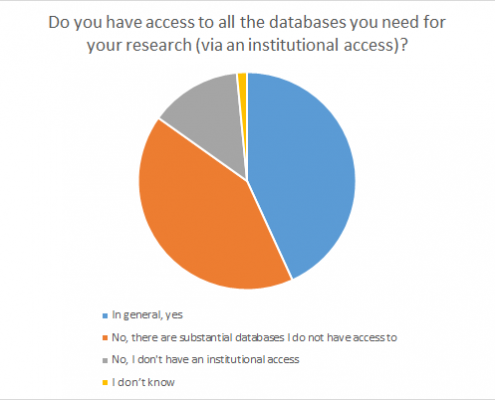
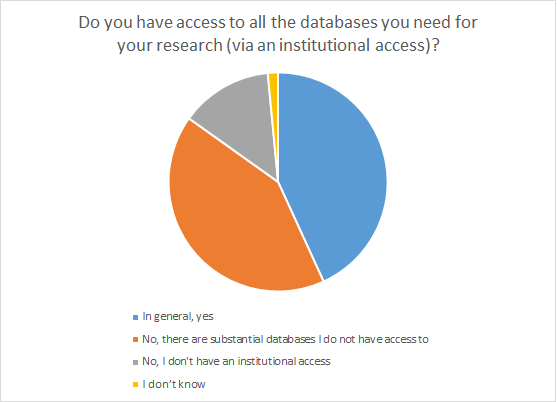
Ill. 7. Access to databases via respective institution.
The diagram shows clearly that the majority of the participants still lack access to the databases needed for their research. Scholars working at German institutions responded markedly more positive to this question. More than 74% confirmed to have access to needed materials. In the optional commentary section, respondents often referred to CrossAsia.
In order to offer access to e-resources, they usually have to be licensed first. The questionnaire shows that the whole process of licensing for science is still rather intransparent. To begin with, only about 17% of the interviewees do not know for sure who may suggest resources for licensing at their institutes. Furthermore, over 31% do not know who at their institutions is involved in the process of evaluating new resources. More than 33% are unable to name the person(s) which ultimately decide on the licensing of e-resources.
Given the urgent necessity to better integrate e-resources into the general supply of information, students and researchers should be more involved in the decision-making process.
Digital Humanities
In the field of DH, methods become usually applicable only when the required e-resources are available and data can be generated. Therefore, the availability of the respective online resources constitute a precondition for the straightforward implementation of DH-projects which need this kind of sources.
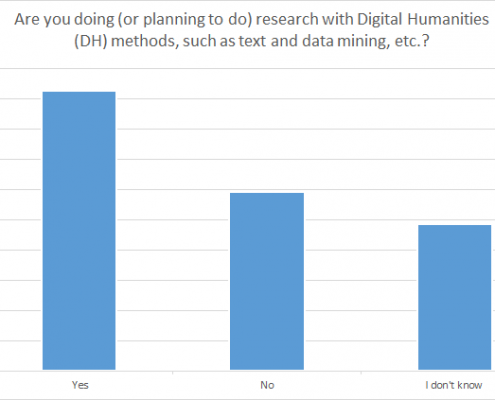
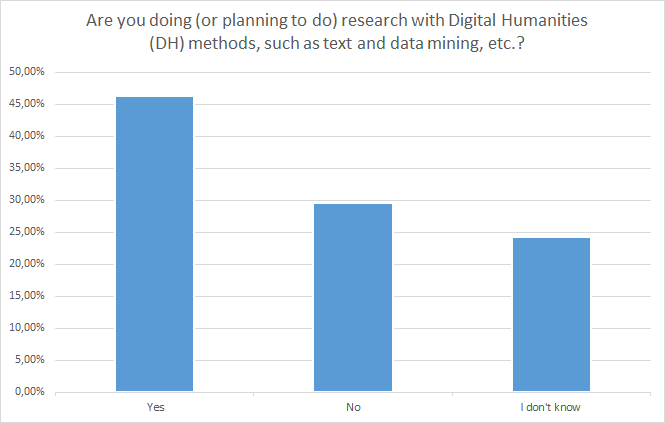
Ill. 8. Usage of DH-methods in research of respondents.
The increased importance of Digital Humanities in China-related research is also evident in the above illustration. It shows that nearly 50% of the respondents are employing DH-methods or are planning to do so. This positive general picture is evenly distributed over Europe.
Regarding the distribution of different tools, we get the following picture:
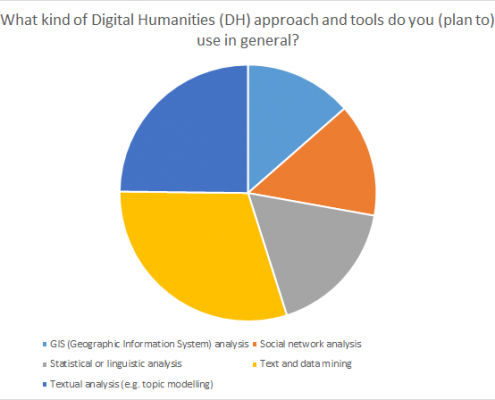
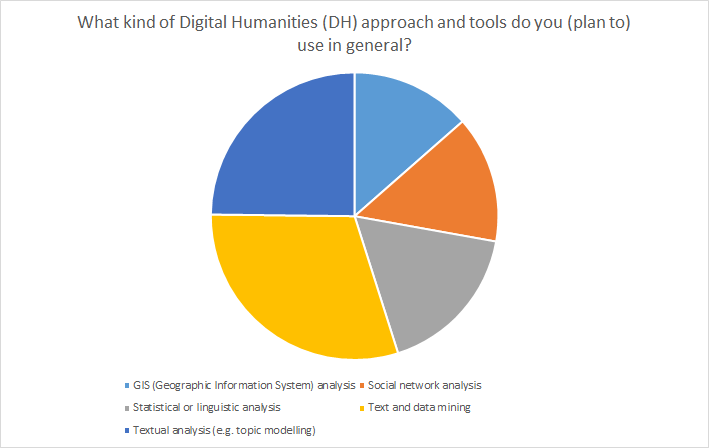
Ill. 9. Distribution of DH-tools used.
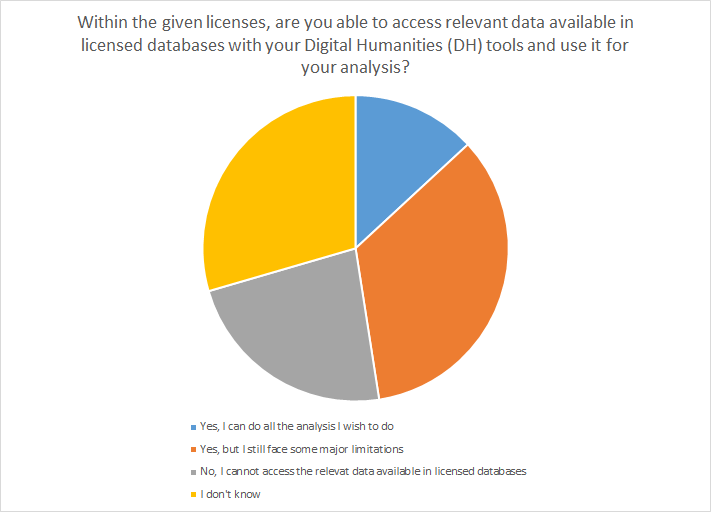
It comes to no surprise that two text-based methods (text and data mining [30%] and textual analysis [25%]) are mentioned most often, since the majority of the participants indicated a philological/historical research background. This is in contrast to the limited availability of the required data. 23% of the respondents stated that they do not have access to the respective materials.
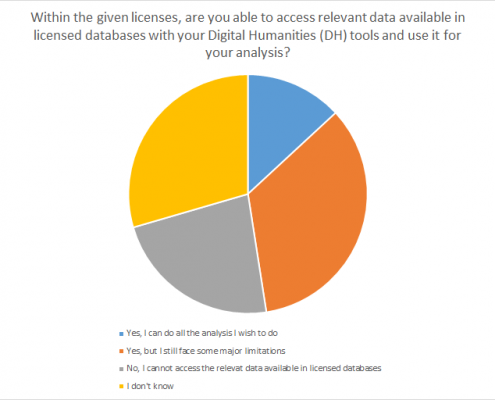
Ill. 10. Access to licensed databases needed to conduct DH-projects.
Networking among researchers was another point of the survey. Its aim was to determine to what extend scholars who do not have access to important resources in their respective countries manage to get this access via an affiliation with international research projects.
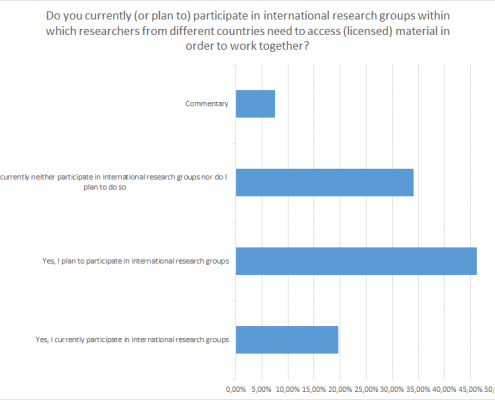
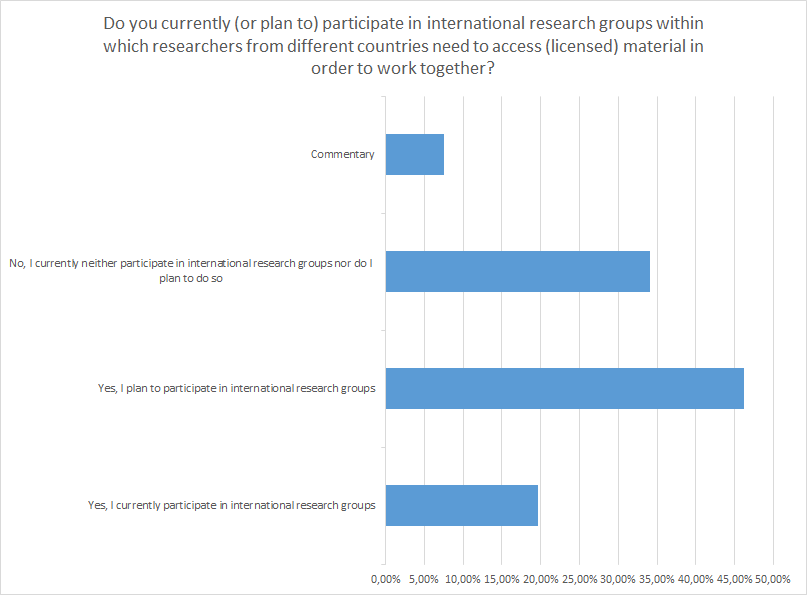
Ill. 11. Percentage, participation of interviewees in international research groups.
In the present European context of China-related sciences, international research groups are still the exception. Only about 20% of the surveyed scholars presently take part in any of them. However, the fact that 45% of the respondents state that they plan to engage in an international research group shows their keen interest. Unfortunately, the cooperation in an international research project does not necessarily result in access to resources. Only 9% of the answers acknowledge access to the resources of the partner institutions, 21% do not have access.
Conclusion
China-related research in Europe is reflected in the survey as humanistically (geisteswissenschaftlich) dominated, with a focus on Mainland China. Access to resources, regardless whether in print or online, is considered as very important. At the same time, access, especially to online materials, is not granted everywhere. One reason for this might be a lack of knowledge surrounding the procedures of licensing.
If these were communicated better, researchers would be enabled to exert their influence in the right places by submitting their suggestions and wishes. One positive exception in Europe is the literature supply in Germany where significantly less researchers have grave problems with obtaining vital information.
It can be safely assumed that the main reason for this is the Special Subject Information Service Asia (FID) with its online offerings in CrossAsia which closely cooperates with the researchers in order to provide the required materials. The numerous mentioning in the survey’s commentaries may be taken as evidence and confirmation.
The results of the survey confirm the expectation that access to e-resources in Europe is still far from being homogeneous. There are big differences between individual countries regarding the provisioning of required materials, while the procedures of licensing individual databases are not transparent.
Today, individual scholars’ high degree of specialisation leads to a wide range of usage requirement and requests. In particular, with regard to the continuously increasing digitisation and the growing number of DH-projects, a united and coordinated approach should be able to more adequately live up to this kind of diversity. In order to facilitate access to electronic media, some things are indespensible: consultation with, and advice from, scholars and librarians in specialized libraries and information centres, the sharing of information surrounding the topic of licensing, and the exchange of experience reports.
Long-term international cooperation and reliable coordination of diverse partners could be and, in our opinion, are, instrumental in improving access conditions for the European research community in general.
The FID Asia considers this its duty. Together with you, we would like to take on this challenge.



 Staatsbibliothek zu Berlin - PK
Staatsbibliothek zu Berlin - PK
 “Kannada” – was ist denn das?
“Kannada” – was ist denn das?