Dear users,
On May 21st at 12:30 pm (CEST), we are pleased to host the fourth session of the CrossAsia DH Lunchtalks 2026. This session will feature a joint presentation by Dr. CHEN Shih-Pei and Dr. Mariana Favila Vázquez, titled “Structures of Knowing an Empire: Building Digital Analytical Tools for Chinese Local Gazetteers and Spanish Relaciones Geográficas.” In this talk, Dr. Chen and Dr. Favila Vázquez will present and compare their digital approaches to analyzing geographical knowledge in early modern China and the Spanish Empire.
How did early modern empires come to know their vast territories, especially the remote regions at their peripheries? In a recent book titled “Knowing an Empire: Early Modern Chinese and Spanish Worlds in Dialogue”, scholars explore how the Spanish and the Chinese empires developed comparable ways to gather, organize, and use knowledge about their local worlds. The Spanish Empire compiled the Relaciones Geográficas (trans. relational geographies) that surveyed the indigenous peoples, lands, and natural resources of its newly acquired, remote territories. In parallel, the Chinese officials compiled difangzhi 地方志 (local gazetteers) since the 12th century to document the local landscapes, people, flora, and fauna of each regions within the vast empire.
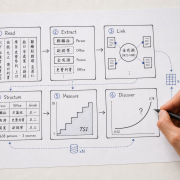
In this CrossAsia DH Lunch talk, two authors who contributed to this book will talk about how they each designed digital analytical tools to help grasp the overall structures of these two genres, given their large amount and rich contents. Shih-Pei Chen will introduce a quantitative analysis based on the section headings of local gazetteers within LoGaRT (Local Gazetteers Research Tools). She argues, the sections headings of each local gazetteer are conscious selection made by its compilers as to how to best describe and document a region, and thus they should be treated as knowledge categories. In this session, she will show how it looks like when analyzing all the section headings from 4000 gazetteers together: it reveals a dynamic structure of “local knowledge” of historical China that is jointly defined by imperial guidelines and local officials across geographical regions over 800 years.
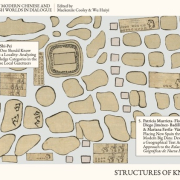
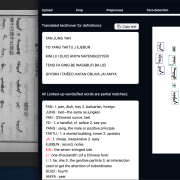
Mariana Favila Vázquez will introduce the case of the sixteenth-century Relaciones Geográficas, a documentary corpus produced in response to a questionnaire of fifty questions circulated in 1577. The questionnaire was commissioned by King Philip II and distributed through the Council of the Indies as part of a broader effort by the Spanish Crown to gather systematic information about its American territories. The instructions and interrogatory were prepared under the direction of the royal cosmographer-chronicler Juan López de Velasco and sent to local authorities in New Spain, who were responsible for compiling the responses.
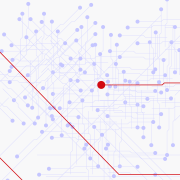
This session will present a case study based on the information contained in the responses from the former Bishopric of Michoacán, with particular attention to references to inland bodies of water. It will also outline the methodology of Geographical Text Analysis, which enables the creation of digital annotations using historically relevant semantic categories and the linking of identified toponyms to their corresponding geographic coordinates, making it possible to conduct subsequent spatial analyses.
The works featured in this talk can also be found at “Part 2: Structures of Knowing” in Knowing an Empire, which is open access and can be read online at Fulcrum.org.
About the speakers:
Dr. CHEN Shih-pei is a Senior Research Scholar at the Max Planck Institute for the History of Science (MPIWG) and a specialist in Digital Humanities. She desgins digital research methods, tools, and infrastructures to help historians engage with digitized historical materials from new perspectives. She has led the development of several DH projects, including the Local Gazetteers Research Tools (LoGaRT); CHMap as a website hosting open-access historical maps of China (in collaboration with Shanghai Jiao Tong University); RISE & SHINE as an API protocols for the standardized exchange of digital texts among digital tools and content providers. At MPIWG, she is now leading another research project: “Common Knowledge and Its Sources in the Sinosphere, 14th–20th Centuries,” which investigate how the Chinese daily-use encyclopedias to examine how “common knowledge” in Chinese history evolved and diverged from elite and literati genres.
Dr. Mariana Favila Vázquez is an archaeologist, and holds an MA and a PhD in Mesoamerican Studies from the National Autonomous University of Mexico (UNAM). Her research focuses on pre-Hispanic and colonial navigation, cultural landscapes, and the use of digital technologies and spatial analysis in historical research. She is the author of Veredas de Mar y Río. Navegación prehispánica y colonial en Los Tuxtlas, Veracruz (UNAM, 2016) and Navegación prehispánica en Mesoamérica (BAR Publishing, 2020), as well as several articles and book chapters. She has held postdoctoral fellowships at Lancaster University and at UNAM’s Institute of Geography. She is currently Associate Professor at the Centre for Research and Advanced Studies in Social Anthropology (CIESAS), Mexico City Unit, in the area of Ethnohistory, where she is developing a project on lacustrine landscapes and digital humanities. She is a member of Mexico’s National System of Researchers (SNII), Level 1.
The lecture will be held in English. If you have any questions, please contact us at ostasienabt@sbb.spk-berlin.de.
The lecture will be streamed and recorded via Webex*. You can take part in the lecture using your browser without having to install a special software. Please click on the respective button “To the lecture” below, follow the link “join via browser,” and enter your name.
You can find the full programm of CrossAsia DH Lunchtalks 2026 here. Further talks will also be announced on our blog as well as on Mastodon and BlueSky.
Yours,
CrossAsia Team
*By participating, you grant the Stiftung Preußischer Kulturbesitz and its subordinate institutions free of charge all rights of usage of pictures and videos taken of you during this lecture presentation. This declaration of consent is valid in terms of time and space without restrictions and for usage in all media, including analogue and digital usage. It includes image processing and the usage of photos in composite illustrations. German law will apply.