
Naval Kishore Press – digital: Digitalisierung und Texterkennung bei Devanagari-Drucken
Der 1858 in der nordindischen Stadt Lakhnau gegründete Verlag Naval Kishore Press (NKP) entwickelte sich in den ca. hundert Jahren seines Bestehens zu einem der bedeutendsten Verlagsunternehmen Indiens. Zu Lebzeiten des Gründers Munshi Naval Kishore (1836-1895) veröffentlichte der Verlag geschätzte 5.000 Titel in den Sprachen Hindi, Sanskrit, Urdu, Arabisch, Persisch und Englisch. Inhaltlich deckte das Verlagsportfolio eine große Bandbreite ab – Schulbücher, Ratgeber, Texte der klassischen Sanskrit-Literatur, Literatur zum Islam, Koran-Ausgaben und Übersetzungen englischer Klassiker, wie z.B. die Dramen William Shakespeares, wurden publiziert. Die CATS Bibliothek / Abteilung Südasien der Universität Heidelberg besitzt mit ca. 2.000 Titeln der Naval Kishore Press einen repräsentativen Querschnitt der Veröffentlichungen dieses bedeutenden Verlagshauses.
Um diesen Schatz für Wissenschaftlerinnen und Wissenschaftler sichtbarer – und vor allem besser nutzbar – zu machen, wurde im Rahmen des FID Asien das Teilprojekt Naval Kishore Press – digital initiiert. Ausgewählte Hindi- und Sanskrit-Titel in Devanagari-Schrift aus der NKP Sammlung werden im Digitalisierungszentrum der UB Heidelberg digitalisiert. Aus diesen Bildfaksimiles werden unter Einsatz der Plattform Transkribus editierbare Volltextversionen erstellt. Die HTR Engine von Transkribus basiert auf künstlicher Intelligenz und wird folgendermaßen angewendet: Zunächst werden von ca. 200 Seiten des zu erkennenden Materials „Ground Truth“ (GT) Transkriptionen erstellt. Dabei handelt es sich um manuell transkribierte 1:1 Wiedergaben des Textes auf dem Bildfaksimile. Die GT und die Bildfaksimile werden verwendet um ein Datenmodell zu trainieren, dessen HTR Algorithmen auf künstlichen neuronalen Netzen basieren und mit dem nun weitere Devanagari-Text automatisch transkribiert werden können. Mit einer Character Error Rate (CER) von 2-5% beim Validierungssatz liefern die beiden trainierten Datenmodelle bereits hervorragende Ergebnisse.
Unsere beiden Devanagari-Modelle zur automatischen Texterkennung haben wir kürzlich über die Transkribus-Plattform zur Nachnutzung freigegeben und hoffen damit allen, die mit Texten in Devanagari arbeiten, die Arbeit zu erleichtern.
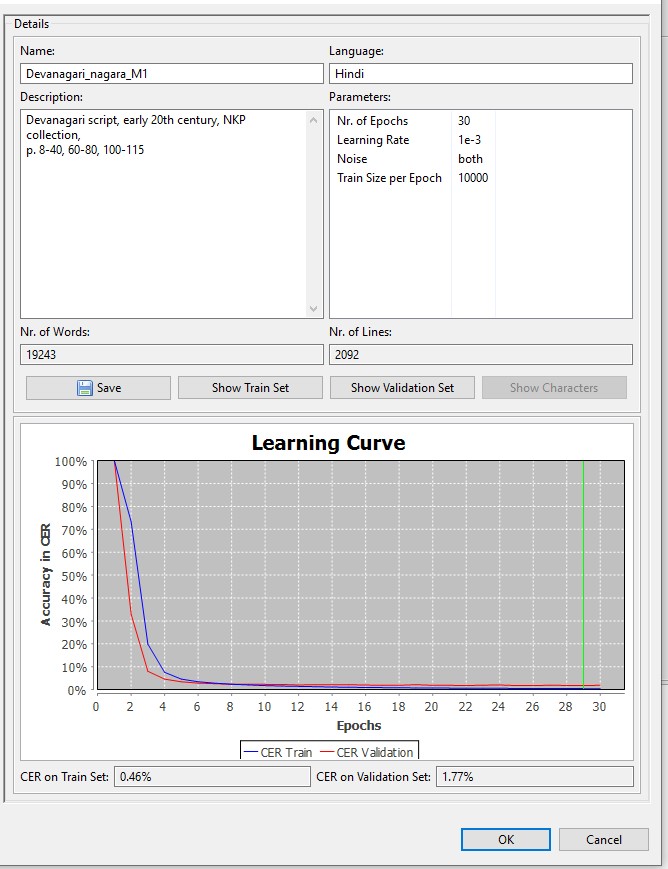
Transkribus Datenmodell „Devanagari nagara M1“
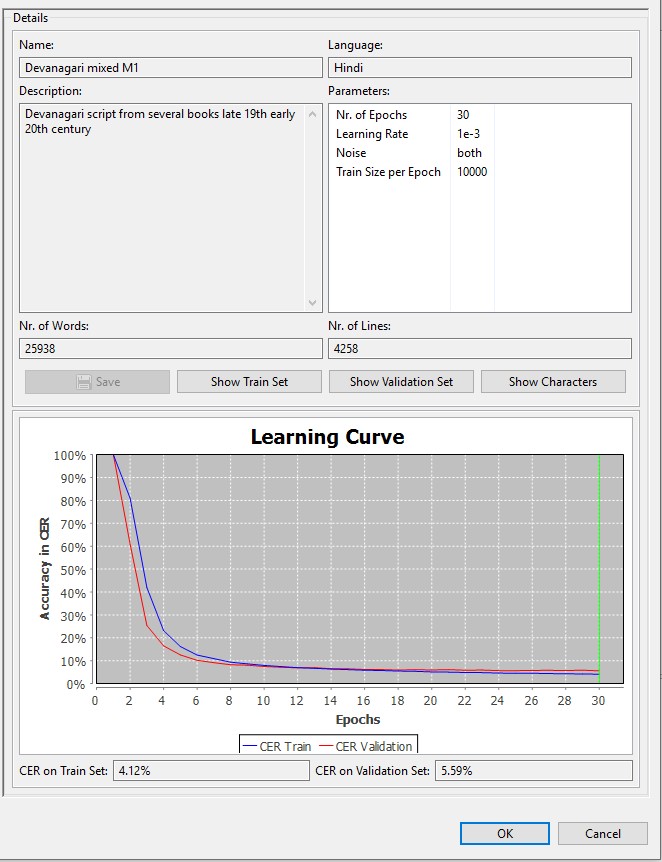
Transkribus Datenmodell „Devanagari mixed M1“
Zugang zu Naval Kishore Press – digital mit den digitalisierten und im Volltext durchsuchbaren Texten haben Sie über die CrossAsia Themenportale. Den Nutzerinnen und Nutzern stehen bei der Webpräsentation eine Vielzahl von Funktionen zur Verfügung, wie z.B. Miniaturbildübersicht, Ein- und Auszoomen sowie Annotationsmodule. Wörter oder Phrasen aus den Hindi- und Sanskrit-Texten können in der Devanagari-Schrift oder in lateinischer Transliteration gesucht werden. Ergebnisse werden im Bildfaksimile sowie in der Volltextversion durch Highlighting der Fundstelle ausgewiesen.

