CrossAsia DH Lunchtalks – Getting the Lines Right: Layout Analysis as the Critical First Step for Tibetan Newspaper HTR
Dear users,
On March 24th at 12:30 pm (CET), we are pleased to host the second session of the CrossAsia DH Lunchtalks 2026. The talk will be given by Dr. Franz Xaver Erhard and is titled “Getting the Lines Right: Layout Analysis as the Critical First Step for Tibetan Newspaper HTR.” Dr. Erhard will introduce his the Divergent Discourses project, as well as TransYolo, a custom Python workflow to solve the layout analysis bottleneck in digitizing historical Tibetan newspapers.
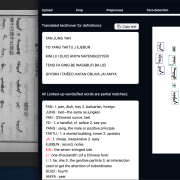
Handwritten Text Recognition (HTR) has matured rapidly in recent years, and for many document types, the core recognition task is largely solved. Yet when researchers turn to historical Tibetan newspapers, progress stalls — not because HTR models fail, but because the lines are never correctly identified in the first place. This talk argues that layout analysis, not transcription, is the true bottleneck in Tibetan newspaper digitization, and that no single off-the-shelf tool is adequate for the task.
Tibetan newspapers such as the Tibet Daily (TID) collection present a combination of challenges that expose the limits of general-purpose layout tools: dense multi-column page designs with inconsistent column spacing, mixed scripts (Tibetan, Chinese, Latin), varying typefaces and handwriting styles across issues and periods, and the physical realities of digitized print — page skew, gutter distortion, and uneven illumination. These properties interact in ways that defeat standard segmentation approaches, producing incorrect line detections, boundary bleed-across, and broken reading order — all before a single character is recognized.
Transkribus, the dominant platform for historical HTR in the humanities, offers built-in layout analysis through its field models. These work well for their intended use cases, but Tibetan newspaper material sits well outside that scope: column layouts confuse region assignment, high line density triggers false positives, and the platform’s limited configurability makes targeted correction difficult. The lesson is not that Transkribus falls short, but that specialized material demands specialized solutions.
To meet this need, the talk introduces TransYolo, a custom Python workflow developed within the Divergent Discourses project (AHRC/DFG). TransYolo uses a YOLO model trained specifically on Tibetan newspaper pages to detect text lines, assigns detections to text regions previously detected with Transkribus, reconstructs reading order, and exports Transkribus-compatible PAGE XML. The example shows what becomes possible when layout analysis is treated as a problem in its own right.
About the speaker:
Dr. Franz Xaver Erhard is a Tibetologist specializing in Tibetan literature, biography, and cultural history, with close to a decade of fieldwork experience in Lhasa. He is the Principal Investigator of the DFG/AHRC cooperative project „Divergent Discourses: Processes of Narrative Construction in Tibet, 1955–1962,“ which compiles and analyses the first modern corpus of historical Tibetan newspapers using digital humanities methods, including computational tools for text recognition and natural language processing, to trace how divergent narratives emerged and evolved in PRC and exile publications during one of the most consequential periods of Tibetan history.
The lecture will be held in English. If you have any questions, please contact us at ostasienabt@sbb.spk-berlin.de.
The lecture will be streamed and recorded via Webex. You can take part in the lecture using your browser without having to install a special software. Please click on the respective button “To the lecture” below, follow the link “join via browser,” and enter your name.
You can find the full programm of CrossAsia DH Lunchtalks 2026 here. Further talks will also be announced on our blog as well as on Mastodon and BlueSky.
Yours,
CrossAsia Team