 By AWeith [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], from Wikimedia Commons
By AWeith [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], from Wikimedia CommonsNoch mehr Volltextsuche für alle!
Seit April steht bereits die erste Version der CrossAsia Volltextsuche zur Verfügung. Wir hatten damals über das CrossAsia Integrierte TextRepositorium (ITR) berichtet, und die Suche als eine Spitze dieses sonst von außen nicht sichtbaren “Eisbergs” kurz vorgestellt. Seither ist viel passiert. Das ITR und die in die Volltextsuche eingebetteten Ressourcen sind kontinuierlich gewachsen und wir konnten jetzt auch eine zweite Variante der Volltextsuche freischalten. Zu beidem finden Sie mehr Details weiter unten. Ein wichtiger Punkt bei der Volltextsuche für uns ist, sie so anzubieten, dass sie *allen* Nutzer*innen zur Verfügung steht, also auch solchen, die keinen Zugang zu den jeweiligen Datenbanken haben bzw. deren Zugang nicht über CrossAsia ermöglicht wird. Damit fügt sich die Volltextsuche harmonisch in das Profil der eher “bibliographischen” CrossAsia Suche ein, die ebenfalls frei zur Verfügung steht.
Schnipsel und Links
Die Treffer in der CrossAsia Volltextsuche werden als sehr kurze und fragmentierte Textschnipsel ausgegeben. Nur so ist es möglich, die Suche für alle zu öffnen und dabei die für diese Ressoucen vereinbarten Lizenzbedingungen zu wahren. Auch Nutzer*innen ohne Zugang zu den jeweiligen Datenbanken wird damit die Möglichkeit gegeben, einen Eindruck zu gewinnen, welche Quellen u.U. relevant für die eigene Fragestellung sind. Über verschiedene Links in den Treffern gelangt man zur kompletten Quelle. Für authentifizierte CrossAsia-Nutzer*innen führt das ‘rot’ gefärbte Icon direkt zum Objekt im originalen Kontext der Datenbank; für Nutzer*innen mit anderen Zugangsmöglichkeiten – z.B. über den IP-Range ihrer Institution oder ein individuelles Login – wird parallel ein ‘graues’ Icon angeboten. “Direkt zur Quelle” bedeutet für die verschiedenen Ressoucen dann doch verschiedenes. In jedem Fall stellen wir möglichst treffgenaue Links zur Verfügung. D.h. wenn der Datenbankanbieter uns das ermöglicht, wird die entsprechende Seite angesteuert, in anderen Fällen gelangt man zumindest zum Buch oder Artikel und muß dort dann die im Treffer angegebene Seite (bzw. Imagenummer) aufschlagen. In einigen Fällen jedoch stehen nur Links zur jeweiligen Datenbank zur Verfügung. Hier ist der Weg dann etwas weiter bis zur Fundstelle (so aktuell z.B. der Fall für die People’s Daily und die Lokalmonographien der Erudition-Datenbank).
Noch mehr Volltexte für die Suche
Der Korpus an Texten, die in der CrossAsia Volltextsuche durchsucht werden können wächst kontinuierlich. Aktuell dominieren chinesische Texte und englische Texte mit Chinabezug, aber weitere Ressourcen, die auch für die Japan-, Korea- und weitere asienbezogene Forschung relevant sind, befinden sich bereits in der Pipeline. Aktuell können die Inhalte der folgenden, über CrossAsia lizenzierten Datenbanken recherchiert werden:
- Adam Matthew – China, America, Pacific
- Adam Matthew – China Trade & Politics
- Adam Matthew – Foreign Office Files China
- 道藏輯要
- 中國地方誌 一集 (雕龍)
- 中國地方誌 續集 (雕龍)
- Missionary, Sinology, and Literary Periodicals (1817-1949)
- Local Gazetteers (Erudition)
- 人民日报 : People’s daily (1946-2009)
- 清代史料
- 四庫全書
- 續修四庫全書
Darüberhinaus sind in die Volltextsuche einzelne lizenzierte Bände aus den Airiti und CNKI ebook-Portalen integriert, sowie ein Testsample an gedruckten Beständen, für die wir selbst mittels OCR einen Index erstellt haben. Zusammen sind das aktuell: 120 Tausend Titel (Buch- und Artikeltitel) mit über 13 Millionen Seiten. Das ist schon eine ziemlich große Eisbergspitze.
Noch mehr Suche für die Volltexte
Einigen Nutzer*innen ist die CrossAsia Volltextsuche Typ A mittlerweile schon vertraut. Jetzt haben wir ihr eine Volltextsuche Typ B zur Seite gestellt. Charakterisieren lassen sich die beiden als “geführte Suche” (Typ A) und “explorative Suche” (Typ B).
Typ A nimmt als Anker für die Suche Einheiten wie z.B. ein Buch oder eine Tagesausgabe der People’s Daily und verwendet die Anzahl der Seiten/Artikel mit Treffern darin als Kriterium für die Reihenfolge der Anzeige. Ein Buch mit mehr Seiten auf denen der Suchterm erscheint, wird also höher gerankt. Die “Anker” bzw. Bücher etc. werden im Suchergebnis in der linken Spalte in diesem Ranking angezeigt; wählt man ein Objekt dort aus, erscheinen die Seiten mit Treffern aus dem ausgewählten Objekt in der mittleren Spalte. Diese sind nach Seitenzahl geordnet. Mit Hilfe der Filter in der rechten Spalte kann man die Treffermenge dann weiter reduzieren bzw. fokusieren. Es wird in Typ A *nur* in den Inhalten der Seiten gesucht und diese Inhalte zu ihren jeweiligen Büchern o.ä. gebündelt ausgegeben.
Hier die Funktionen der drei Seitenbereiche von Typ A im Überblick:
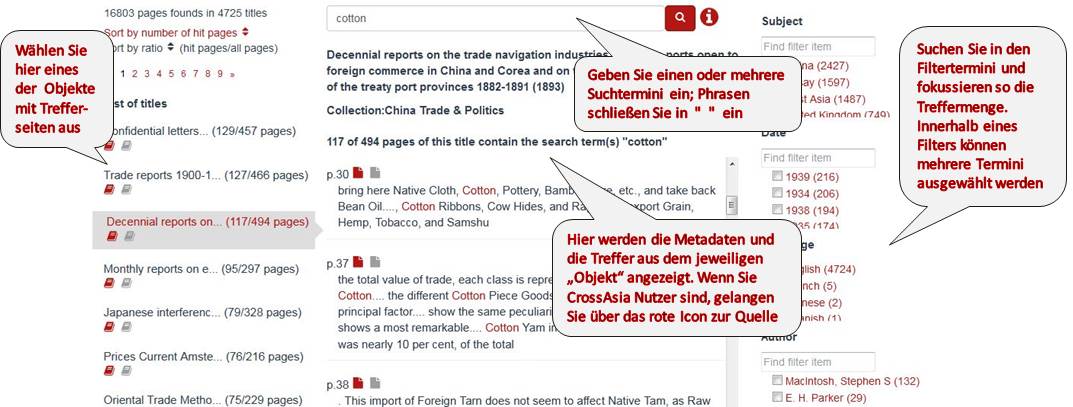
Typ B behandelt alle Objekte gleichberechtigt. D.h. Bücher, Artikel oder Archivalien und die einzelnen Volltextseiten werden auf ihre Relevanz in Bezug auf den Suchterm vom Index bewertet und in der Reihenfolge dieser Bewertung (dem “score”) als Treffer ausgeliefert. Metadaten, Bescheibungen, Autorennamen, Volltexte – alles wird durchsucht und in bunt gemischter Reihe ausgegeben. Über Filter auf der linken Seite kann der Typ der Trefferobjekte gewählt werden (also ob nur Seiten oder nur Bücher bzw. Artikel und ihre Metadaten ausgeben werden sollen) oder auch Filter wie Jahr, subject u.ä. eingestellt werden. Dies kann wiederum nachträglich geschehen, in Typ B aber auch bevor ein Suchterm eingegeben wurde. Zu beachten hier ist, daß aktuell für Seiten keine inhaltlichen Filter zur Verfügung stehen. IE jenseits von Edge setzen die Filterfunktion nicht korrekt um.

Einen kurzen Überblick gibt auch die neue Einstiegsseite für die CrossAsia Volltextsuche. Mehr Informationen zu den jeweiligen Besonderheiten der beiden Such-Typen können über das “i” hinter den Suchschlitzen aufgerufen werden.
Und was kommt dann?
Beide Suchmodi lösen Schranken zwischen verschiedenen Quellenkorpora und Texttypen auf, die durch die individuellen Datenbankzugänge geschaffen wurden, und ermöglichen damit – so hoffen wir – neue, bessere Wege, sich einen Überblick über die Quellenlage zu verschaffen und das Umfeld eines Suchterminus in einem möglichst breiten Spektrum von Texten zu ergründen. Details aus verschiedenen Datenkorpora werden gemeinsam angezeigt und werden jenseits der von der Datenbank vorgegebenen Logik ansteuerbar. Das ist ein wichtiger, aber doch auch nur ein erster Schritt. Um sich in diesen großen Mengen an Text nicht zu verlieren, wollen wir gemeinsam mit unseren Nutzern überlegen, wie innovative Rechereche- und Zugangsmodi aussehen könnten. Um zudem diese große Menge an Text für neue Forschungsfragen in den digitalen Geisteswissenschaften zu erschließen, arbeiten wir an Schnittstellen, über die Projekte (große und individuelle) mit diesen Daten in Zukunft arbeiten können, aber auch an Wegen über ein pre-processing diese Texte nicht nur über die Metadaten ihrer bibliographischen Einheit zu charakterisieren, sondern auch “aus sich selbst heraus”, d.h. mit Hilfe von automatisierter Textanreicherung und statistischen Auswertungen von Kollokationen u.ä. weitere Formen von “Metadaten” zu generieren.
Über Hinweise, Feedback, Vorschläge, Kritik sind wir dankbar! Am besten direkt an x-asia@sbb.spk-berlin.de
(For a short English description of the CrossAsia Fulltext Search and the two types of searches please go to the entry page of CrossAsia Fulltext Search and the “i” next to the search slot in both versions of the search)


Diskutieren Sie hierzu im CrossAsia Forum