Der Aufbau einer Infrastruktur für Meta- und Volltextdaten bildet als Aktionsfeld 4 einen zentralen Teil der Aufgaben, die sich CrossAsia im Rahmen der ersten FID-Phase gestellt hat. Wie kurz auf unserer Seite “Über CrossAsia” ausgeführt, dient das “Integrierte Text-Repositorium” CrossAsia ITR zum einen der Aufgabe, Texte, Bilder und Metadaten der für CrossAsia lizenzierten Datenbanken sicher und nachhaltig zu archivieren, zum anderen bietet es die Möglichkeit, diese Inhalte nahtlos in aktuelle und zukünftige CrossAsia Services einzubinden und im Rahmen der digitalen Wissenschaften für Analysen, Explorationen, Anreicherungen und Visualisierungen anbieten zu können. Das ITR ist dabei nicht *nur* ein Lager (z.B. auch für Forschungsdaten), sondern eine komplexe Infrastruktur mit Workflows und technischen Routinen für das Einspielen, Verwalten, und die Bereitstellung der Objekte des ITR (siehe Abbildung 1).
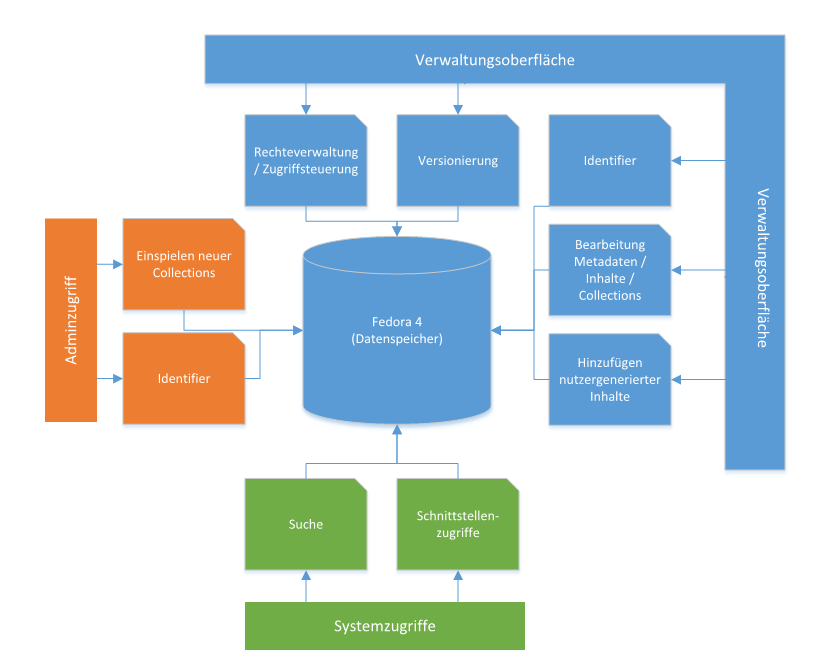
Abbildung 1: CrossAsia ITR Systemarchitektur
Wo finde ich denn das CrossAsia ITR und was ist drin?
Wie bei Lagern, Magazinen, Repositorien zumeist die Regel, ist auch das CrossAsia ITR vor allem Infrastruktur, d.h. es *ermöglicht* Dinge ohne selbst unmittelbar sichtbar und greifbar zu werden. Mit einer Reihe von Metadaten ragt das ITR, wie die Spitze eines Eisbergs, jedoch bereits in die CrossAsia Suche hinein. Dies sind z.B. alle 5.445 Titel des Xuxiu Siku quanshu, die 299 Titel aus dem Daozang jiyao, 7.099 eBook Titel, die über Airiti als PDA angeboten werden, und 7.892 Objekttitel der Foreign Office Files China. Einen Überblick darüber, was aktuell in die CrossAsia Suche integriert ist, erhalten Sie bei Klick auf das “i” neben dem Suchschlitz der CrossAsia Suche. Wie gewohnt bieten diese Treffer einen CrossAsia Link, mit dem das Objekt in der Datenbank aufgerufen werden kann.
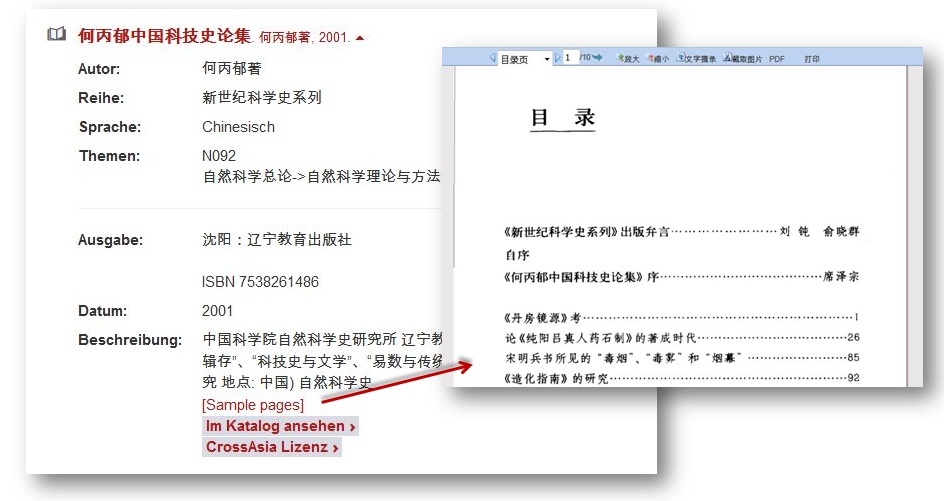
Weitere Kontingente an Metadaten und digitalen Objekten, die entweder bereits ins ITR integriert sind bzw. sich auf dem Weg dorthin befinden, sind die Metadaten der Zhonghua Ancient Book und Pishu Datenbanken, die Metadaten und Texte der Renmin Ribao (1946-2009) und Zhongguo fangzhiku, sowie Metadaten, Texte und Images der Datenbanken Meiji Japan, Siku quanshu, Qingdai shiliao, China, America and the Pacific, sowie China, Trade and Culture (Stand April 2018). Die Idee und Aufgabe von Metadaten-Objekten im ITR ist auch, eine Art “Regalplatz” zu bilden, an dem in Zukunft z.B. das PDF des gesamten Titels abgelegt werden kann und Volltexte und digitale Bilder der Einzelseiten des Titel angehängt werden können. Alle Objekte des ITR sind adressierbar und werden mit Zugriffsrechten versehen.
Die Volltexte dieser im ITR archivierten Objekte können über eine “CrossAsia ITR Suche” von Nutzerinnen und Nutzern recherchiert werden, um relevante Texte im CrossAsia Angebot zu entdecken und diese dann in den entsprechenden Datenbanken authentifiziert aufrufen zu können. Das ist sozusagen die zweite Spitze des ITR-Eisbergs. Die Volltext-Ressourcen des ITR werden seit April 2018 in zunächst einer prototypischen Beta-Version für eine CrossAsia Volltext-Suche eingebunden; demnächst folgt eine zweite Beta-Version mit anderen Suchoptionen. Dazu in Kürze mehr für Sie zum Testen und mit Erläuterungen der Funktionalitätenhier im Blog.
Experimentelle und analytische Zugänge zu den Objekten des ITR
In Zukunft wird das ITR uns und unseren Nutzerinnen und Nutzern weitere, deutlich flexiblere und auch experimentelle, explorative und analytische Zugänge und Gesamtschauen von Beständen bieten. Um Nutzerinnen und Nutzern das direkte Arbeiten mit den Beständen mittels digitaler Tools zu ermöglichen wird das ITR mit Schnittstellen ausgestattet, die – unter Einhaltung der Lizenzbedingungen – ein möglichst nahtloses Arbeiten mit den Volltexten ermöglichen sollen (für einen Entwurf einer Struktur, die diese Zugriffe reguliert und ermöglicht, siehe Abbildung 2).
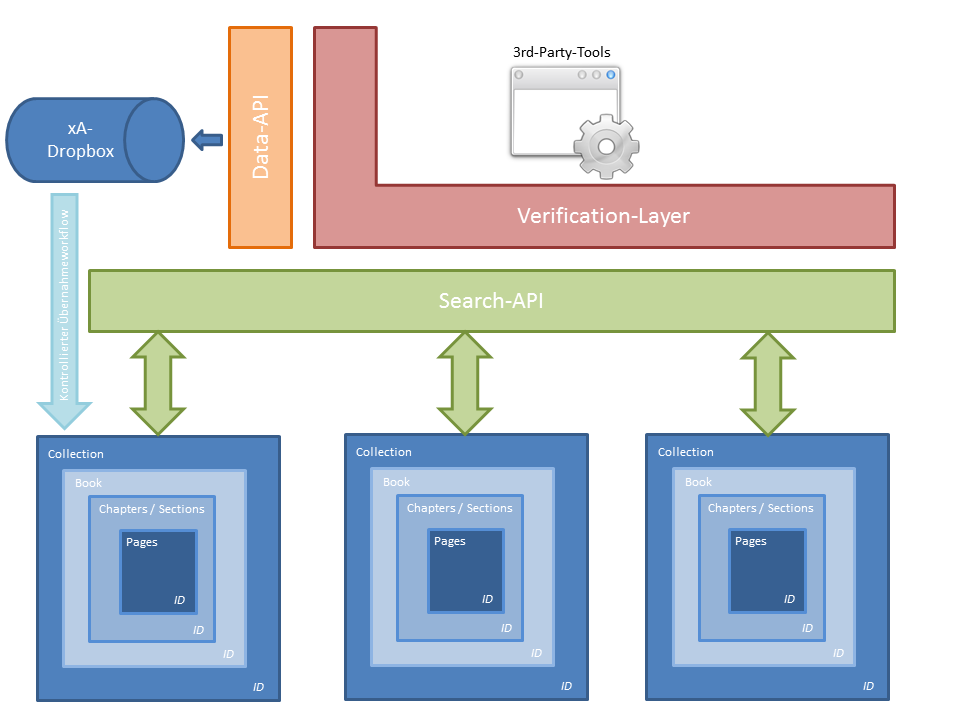
Abbildung 2 – Architektur Schnittstelle
Das ITR soll weiterhin als Arbeitsplattform ausgebaut werden, die es einzelnen Nutzerinnen und Nutzern sowie Forschergruppen erlaubt, z.B. eigene Transkriptionen und Erschließungen von gescannten Texten und Bildmaterialien zu erstellen und diese über kontrollierte Workflows in das ITR zurückzuspielen und dort zu sichern, um sie wiederum über die ITR Suche anbieten zu können.
Das CrossAsia ITR hat das Ziel, der CrossAsia Community eine neue Sicht auf und neue Formen der Recherchen in den über CrossAsia angebotenen Materialien zu ermöglichen. Damit wollen wir Rechercheangebote für die digitalen Wissenschaften von heute entwickeln und die Grundlage für Forschungsanliegen von morgen legen. Das CrossAsia Team freut sich darauf, die Möglichkeiten der Recherche in den Volltexten des ITR gemeinsam mit der Community auszutesten und die Entwicklungen weiter voranzutreiben. Wir freuen uns über Ihre Rückmeldungen, Verbesserungsvorschläge und Ideen.
Über die neue Kategorie im CrossAsia Blog zu “ITR und Entwicklungen” halten wir Sie über die weiteren Entwicklungen auf dem Laufenden.