
CrossAsia ITR Explorer
Vor über einem Jahr haben wir begonnen eine Suche über jene Volltexte anzubieten, die bereits im CrossAsia ITR (Integriertes Text-Repositorium) angekommen sind. Der Korpus, in dem gesucht wird, ist mittlerweile auf 26 Datenbankressourcen mit zusammen 52,8 Millionen Seiten in über 325.000 Titeln angewachsen (eine Liste der Ressourcen finden Sie auf der Einstiegsseite zur Volltextsuche). Damit steht allen interessierten Nutzerinnen und Nutzern – auch jenseits einer CrossAsia Authentifizierung – ein sehr großer, stetig expandierender Suchraum zur Verfügung.
Um die „unendlichen Weiten“ des ITR Textkorpus zu erforschen, möchten wir Ihnen heute einen weiteren Zugang vorstellen: den CrossAsia ITR Explorer. Ziel des ITR Explorers ist es, Ihnen in Zukunft eine Reihe von Möglichkeit anzubieten, um Suchergebnisse zu generieren, miteinander zu vergleichen, zu analysieren und zu visualisieren. Wir haben hier eine Reihe von Ideen im Kopf (und in Planung), möchten Ihnen aber heute einen ersten Aufschlag hierzu präsentieren.
Was bietet der CrossAsia ITR Explorer aktuell?
Der Suchraum des ITR Explorers ist identisch mit der CrossAsia Volltextsuche, er erlaubt aber mittels der Operatoren ∩ (AND) und – (AND NOT) sehr viel komplexere, verschachtelte Anfragen an die Volltexte zu stellen. Jede Anfrage generiert ein einfaches Ergebnis-Set (d.h. ein bestimmter Begriff kommt in einem Buch/Artikel vor) und diese Sets können dann über die genannten Operatoren verknüpft werden, um so nach und nach beliebig lange logische Ketten zu bilden (z.B. in welchen Titeln ist Begriff A und B aber nicht Begriff C enthalten). Sollen Begriffe auf derselben Buchseite erscheinen, müssen Sie diese in einer Abfrage mit SPACE verbinden („A B“) – ganz wie in der Volltextsuche. Der Explorer erlaubt Ihnen jedoch, sich einen Fundus an solchen Abfragen zusammenzustellen und diese dann miteinander zu kombinieren, sowohl „logisch“ über Operatoren, als auch „visuell“ über Mengendiagramme bzw. Zeiträume. Der ITR Explorer ist somit ein Werkzeug, sich im Textkorpus besser zu orientieren, indem er erlaubt, Suchtermini in ihrem Zusammenspiel mit anderen Termini und über die Zeit zu verorten und zu visualisieren.
Diesen Ansatz, den ITR Suchraum „begehbar“ zu machen, möchten wir in Zukunft mit weiteren Modulen ausbauen. Dabei denken wir auch an stärker analytische Zugänge. Im folgenden einige Beispiele, wie so eine Anfrage und die Ergebnisse aussehen können. Auf der Eingangsseite des ITR Explorers finden Sie eine kurze Schritt-für-Schritt Anleitung.
Nehmen wir an, Sie haben aus Suchbegriffen und deren Kombinationen folgende Ergebnis-Sets gebildet:
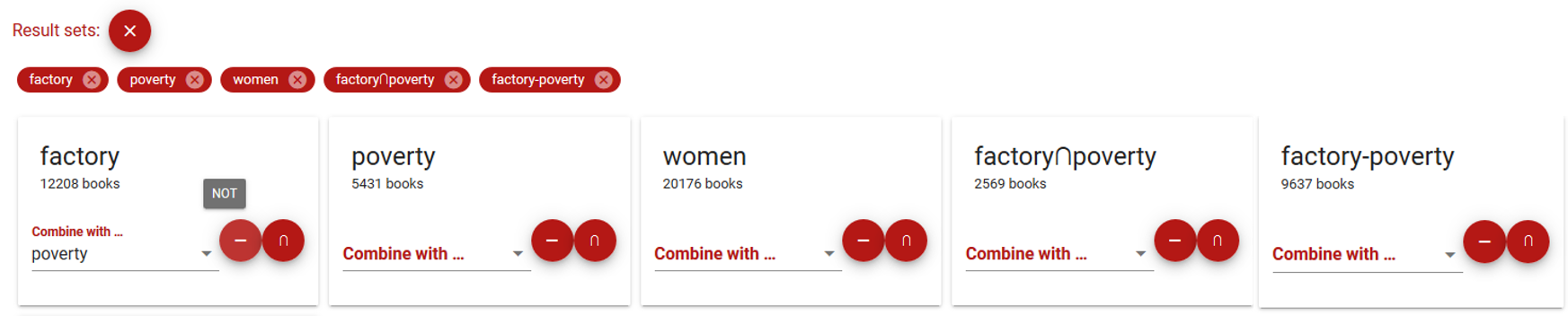
Was zeigen die beiden Visualisierungen?
Die Visualisierung Venn (Overlap) diagram erlaubt AND Verknüpfungen auch interaktiv, sozusagen „on the fly“ zu erstellen und die verschiedenen Ergebnisse und die Titellisten, auf die das ausgewählte Kriterium zutrifft, direkt anzuzeigen. Deshalb hier eine Visualisierung der drei einfachen Ergebnis-Sets „women“, „poverty“ und „factory“.
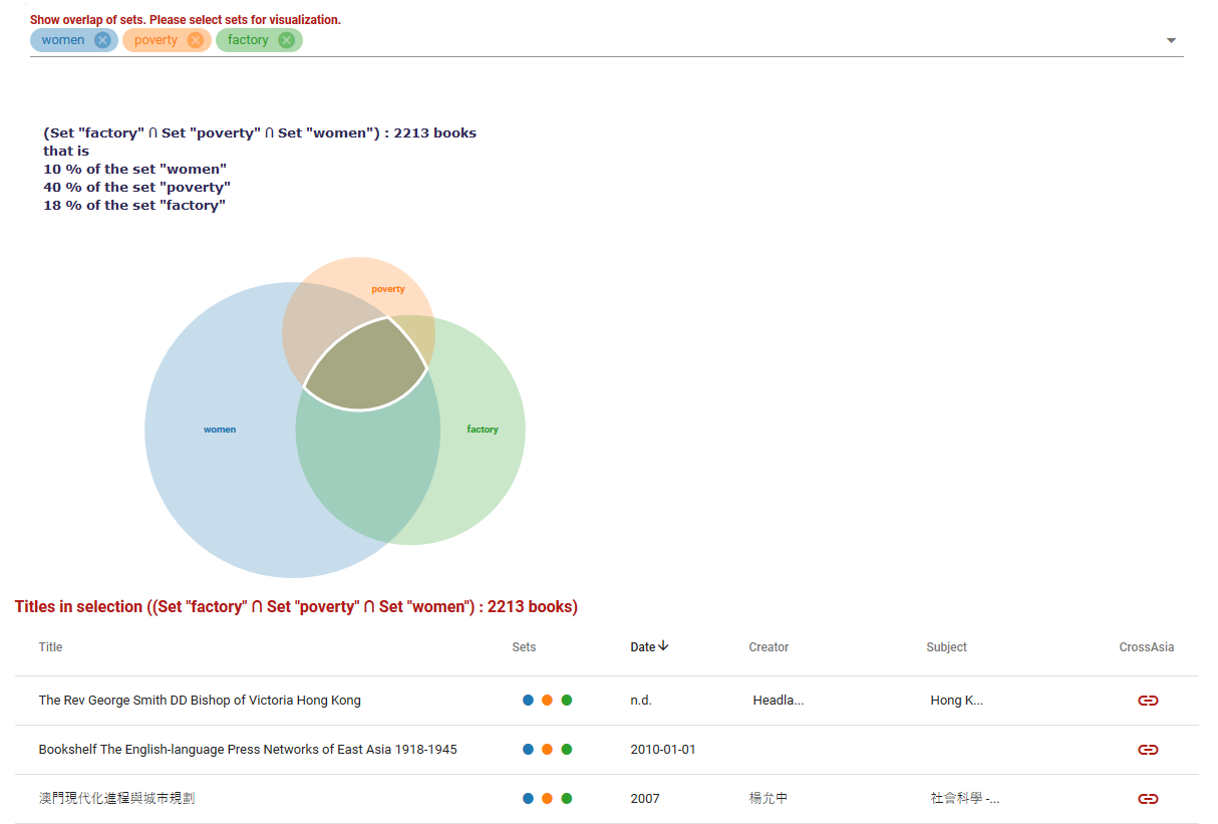
Jedem Ergebnis-Sets wird eine Farbe zugeordnet und die Visualisierung zeigt, in welchem Rahmen sich die Sets überschneiden. Das ausgewählte (weiß umrahmte) Segment enhält Titel, in denen alle drei Begriffe vorkommen. Die Legende oben links gibt an, wieviel Prozent aller Titel z.B. aus der Treffermenge „women“ auch in die gewählte Schnittmenge fallen – im Beispiel sind das 10%. Unterhalb des Diagramms erscheint nach der Auswahl eines Segments die Liste der Titel, auf die die gewählten Kriterien zutreffen; die Liste kann nach Datum und nach Set geordnet werden. Die farbigen Punkte in der Spalte „Set“ markieren in welchen Ergebnissgruppen der Titel vorkommt (z.B. wenn nur die Schnittmenge „women“ und „factory“ gewählt wurde, kann man sehen, welche auch dem Kriterium „poverty“ genügen würden). Über den CrossAsia Link kommen Nutzerinnen und Nutzer von CrossAsia wie gewohnt zur Ressource im Kontext der originalen Datenbank. Ist das Link-Symbol *grün*, dann steht die Ressource frei zur Verfügung.
In der Visualisierung als Line chart (time range) lassen sich die Ergebnis-Sets über eine Zeitachse anzeigen; mittels Anpassen des grauen Bereichs im kleineren Diagramm darunter, kann man die Anzeige der Titel auf eine bestimmte Zeitspanne fokussieren. Auch hier kann man interaktiv, „on the fly“ Anpassungen vornehmen. Die farbigen Punkte in der Spalte „Set“ geben wiederum an, welchem Suchkriterium in Bezug auf „enthaltener Begriff“ der Titel genügt. Im Beispiel unten sind die beiden (sich gegenseitig inhaltlich ausschließenden) kombinierten Ergebnis-Sets „alle Titel, in denen beide Begriffe ‚poverty‘ UND ‚factory‘ vorkommen“ und „alle, in denen ‚poverty‘ aber NICHT ‚factory‘ vorkommen“ dargestellt.
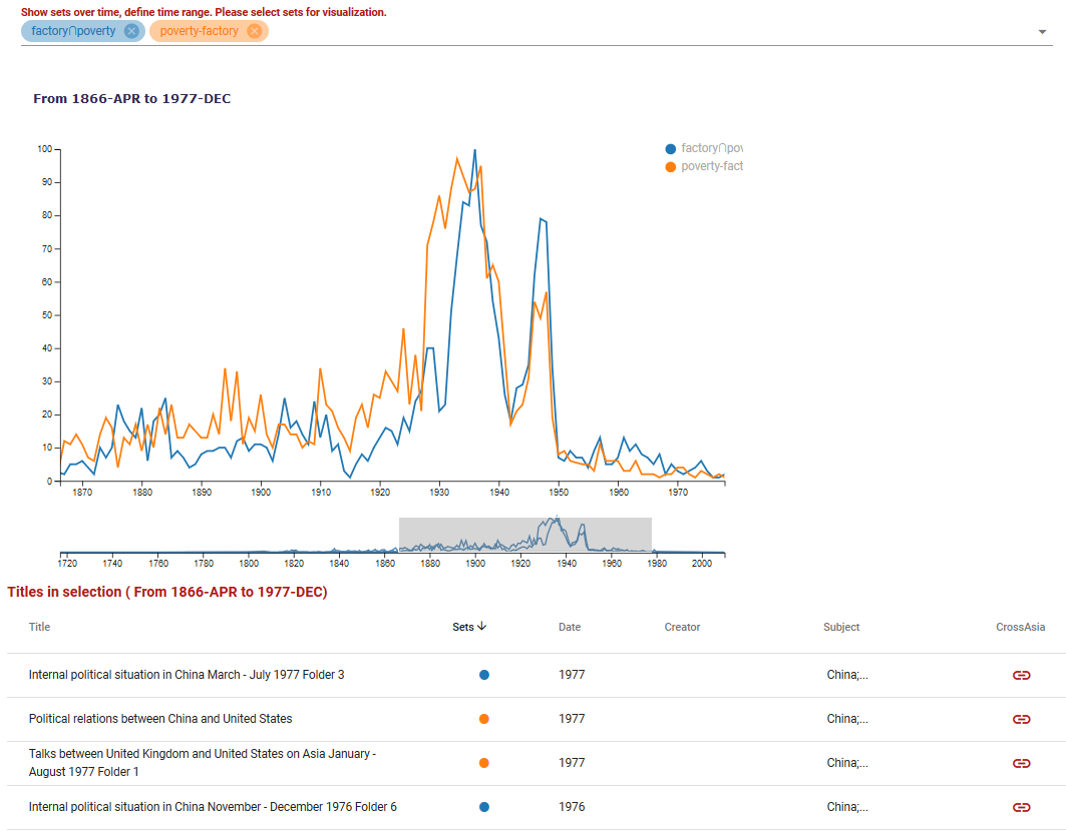
Man kann sehen, wie sich die Menge der Titel aus den beiden Sets mit Erscheinungsdatum zwischen 1866 und 1977 über diesen Zeitraum verändert haben. Hier lassen sich u.U. einige Ideen für weitere Recherchen zu diesem Thema entwickeln. Die absoluten Zahlen an Titeln sollten jedoch nicht vorschnell für analytische Schlüsse verwendet werden. Denn – vor allem im Zeitdiagramm – bildet sich stets sehr deutlich auch die aktuell zur Verfügung stehende Sammlung an Volltexten im ITR ab. Es ist immer auch ein Abbild der Sammlung, das Sie dort sehen!
Noch ein paar Hinweise
Auf zwei Dinge möchten wir zum Schluss noch hinweisen. Zum einen wird aktuell bei den Treffern für einen Begriff nicht qualifiziert ob er einmal oder hundertmal vorkommt. Wir überlegen aber schon, wie wir eine Qualifizierung der Mengen anzeigen können, ohne das System zu zäh und langsam zu machen. Zum anderen sind die angegebenen Mengen an Titeln absolut nicht relativ, d.h. man sieht – vor allem im Liniendiagram – aktuell sehr deutlich, wie sich der ITR Textkorpus über die Zeit verteilt. Wie sich besondere Themen u.ä. vor diesem Hintergrundbrummen darstellen, ist aktuell nur sehr unscharf zu erkennen. Deshalb noch einmal die Warnung, hier keine falschen Schlüsse zu ziehen, und der Hinweis auf einen XKCD Comic, der solche Irrtümer besonders anschaulich macht.
Auch der ITR Explorer steht allen frei zur Verfügung; die Zugänge zu den lizenzpflichtigen Ressourcen ist jedoch CrossAsia-Nutzerinnen und Nutzern vorbehalten.
Über Anregungen und Feedback freuen wir uns! Schreiben Sie uns an x-asia@sbb.spk-berlin.de.
