CrossAsia DH Lunchtalks – AI for the Humanities: A Case of Manchu OCR
Dear users,
On February 3rd at 12:30 pm (CET), we are pleased to host the first session of the CrossAsia DH Lunchtalks 2026. The talk will be given by Dr. Yan Hon Michael Chung and is titled “AI for the Humanities: A Case of Manchu OCR.” Dr. Chung will introduce the development pipeline for creating an OCR model for Manchu-language documents and share his reflections on applying AI to humanities research.
Manchu, today an endangered language, was once the official language of China’s last imperial dynasty, the Qing (1644–1911). The Qing state produced an enormous corpus of Manchu-language documents, many of which have been digitized and made publicly available by archives and libraries worldwide. Despite this abundance of scanned materials, there is still no reliable, publicly accessible optical character recognition (OCR) system for Manchu, posing a major bottleneck for historical research.
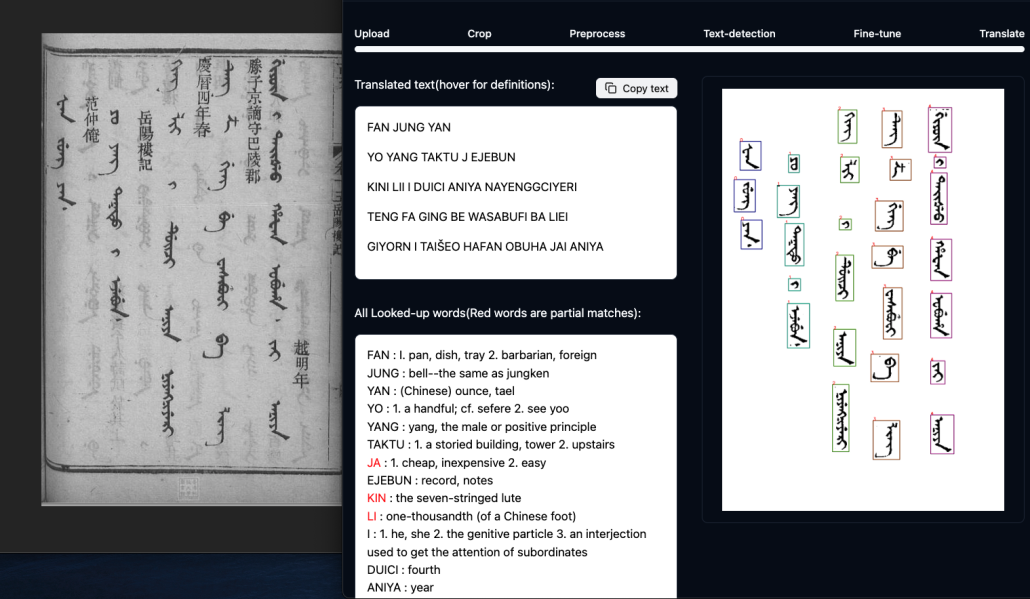
This presentation introduces an end-to-end Manchu OCR system developed by fine-tuning a vision–language model (VLM), and uses it as a case study to reflect on the broader challenges of applying AI to humanities research. It identifies three structural constraints that distinguish humanities-oriented AI development from commercial or industrial settings: the scarcity of labeled training data, the unusually high accuracy requirements demanded by scholarly research, and the limited computational resources available to most humanities scholars.
To address these constraints, the project adopts a small-model, data-centric strategy. The OCR model is trained using a combination of large-scale synthetic data and carefully curated historical samples. Specifically, a LLaMA-3.2-11B Vision model is fine-tuned using approximately 60,000 synthetic Manchu images alongside 20,000 Manchu word images extracted from real Qing-era documents. The resulting model achieves up to 96% accuracy on unseen, real-world scanned Manchu sources.
The OCR pipeline is further enhanced through a custom Manchu word detection and segmentation model, combined with a post-processing large language model for typographical correction. Together, these components form a complete, practical Manchu OCR system built with state-of-the-art vision–language and language models. Beyond presenting technical results, this presentation argues that carefully constrained, accuracy-driven AI systems offer a viable and sustainable path for AI research in the humanities.
About the speaker:
Dr. Michael Chung is an Assistant Professor in Digital Humanities at the Hong Kong University of Science and Technology. Chung received his PhD in history from Emory University in 2025, and his BA and MPhil from the Chinese University of Hong Kong in 2012 and 2016 respectively. Chung’s research centers on the early Qing dynasty, with a focus on the transfer of European artillery technology and the formation of the Hanjun Eight Banners. As a digital humanist, Chung is currently developing a Manchu OCR system based on a fine-tuned vision-language model.
The lecture will be held in English. If you have any questions, please contact us at ostasienabt@sbb.spk-berlin.de.
The lecture will be streamed and recorded via Webex. You can take part in the lecture using your browser without having to install a special software. Please click on the respective button “To the lecture” below, follow the link “join via browser,” and enter your name.
You can find the full programm of CrossAsia DH Lunchtalks 2026 here. Further talks will also be announced on our blog as well as on Mastodon and BlueSky.
Yours,
CrossAsia Team


Diskutieren Sie hierzu im CrossAsia Forum